AWS Athena Query against S3 Table with Python
Athena query plays a pivotal role within the AWS ecosystem. Most data in AWS (excluding RDS) is stored in S3 buckets. Users can easily create tables from files in S3 using Athena DDL, supporting various formats such as CSV, JSON, and Parquet. This enables the use of SQL to analyze the data in these files. Additionally, Athena offers superior query performance compared to regular RDS queries by automatically executing queries in parallel for large datasets. However, a drawback of this approach is that S3 files cannot be modified like traditional database tables, prompting AWS to introduce S3 table bucket to address this limitation since Nov 2024.
To make it simple, we call Athena tables sourced from S3 files as regular Athena tables. We will simply call S3 tables for S3 table bucket type.
There is little difference in the AWS console between these two types of tables; the main distinction is the need to select the catalog when querying an S3 table.
For a data scientist, I am more interested in how to get data from S3 table programmatically.
However, querying S3 tables using the Python Boto3 API differs significantly from querying regular Athena tables. Unfortunately, online materials on this topic are scarce, and it took me quite some time and assistance from an IT colleague to figure it out.
Firstly, let’s review the Python code for querying regular Athena tables. For detailed explanations, please refer to this link.
The steps involved are:
- Pass the query to client start_query_execution and obtain the execution ID
- Use the execution ID with client get_query_execution to retrieve the S3 file
- Read the S3 file into a Pandas DataFrame (refer to this for guidance)
For querying S3 tables:
please note: you need to create boto3 client like you do somewhere else. Here I just use client(env) to represent that steps.
- You still need to obtain the execution ID, but you must include the catalog name if your environment has multiple source layers (e.g., different catalogs for production and development environments).
- Unlike regular Athena tables, you do not need an output location for athena query. Please note, you need to replace your database, catalog info. I replaced those for protecting privacy.
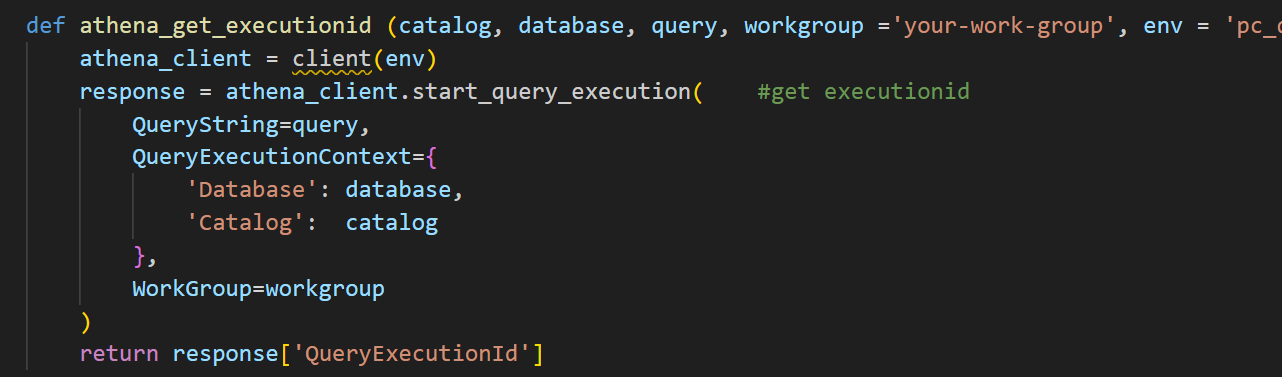
- Retrieving results from an S3 table is different; it does not allow more than 999 rows per retrieval. To overcome this, use a while loop to gather all results. I isolate this part of code as one function to make code less complicated.
- The query results from S3 tables are output in varchar format by default. Metadata, including column names and data types, is available in the same response and stored as variables.
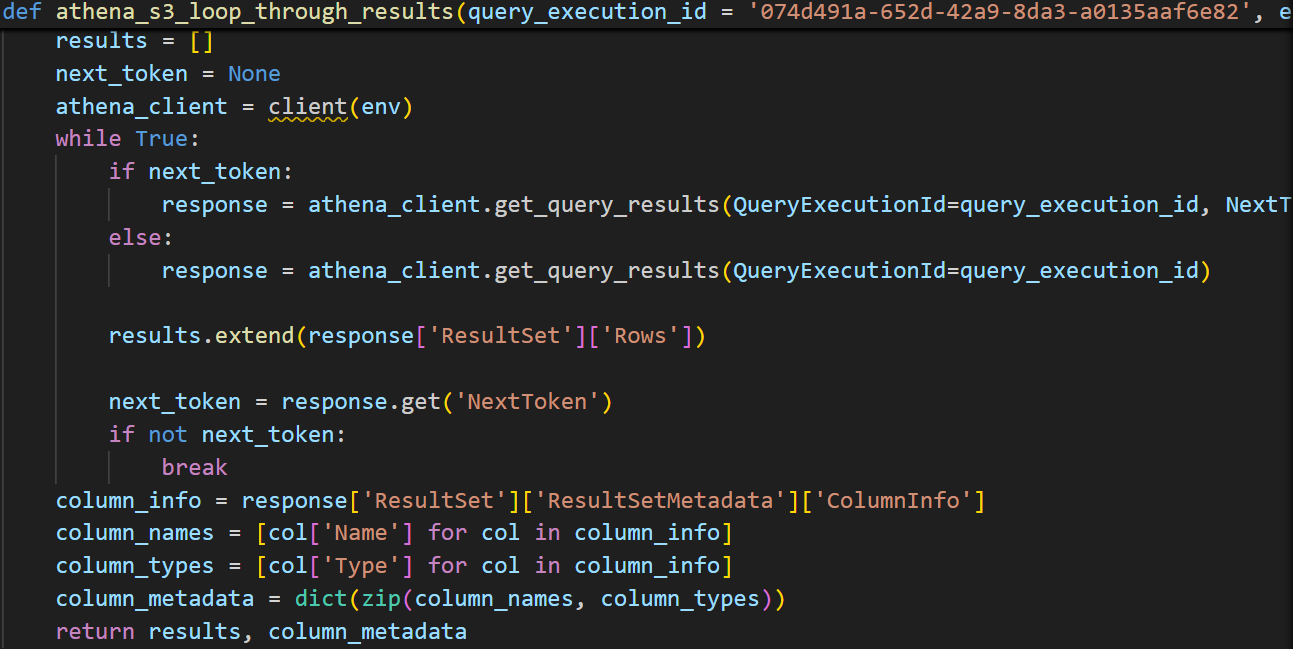
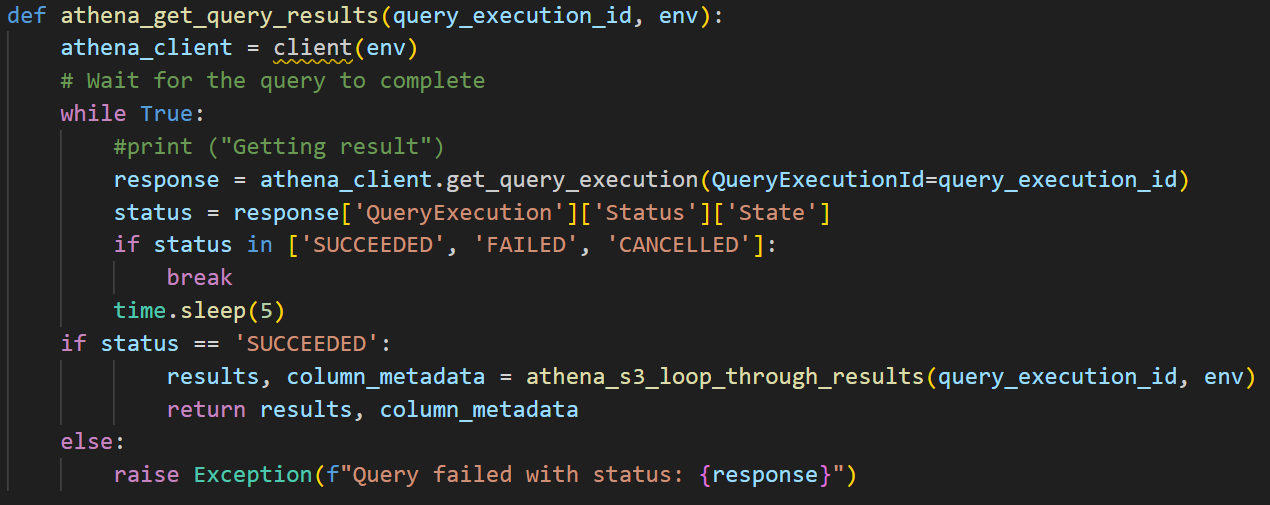
- In the get_result function, the process is similar to querying regular Athena tables, We need to wait till SUCCESS to call previous functon to get results.
- Lastly, I converted the results into a Pandas DataFrame by passing the data and metadata.

I tried to automate date type conversion, but it turns out more difficult than I thought. The reason is Hive based data type and C based data type has different range. See the typical error it shows.
Therefore, I think data type conversion at post data extraction might be a better choice. Also for decimal result, it will only keep 2 decimal points by default. This setting cannot be changed either. Not sure why AWS is so rigid about this. Maybe it is a growing pain. But it might impact high accuracy calculations.
Ultimately, I have combined all the functions so that once a query is passed, the result is returned as a DataFrame.
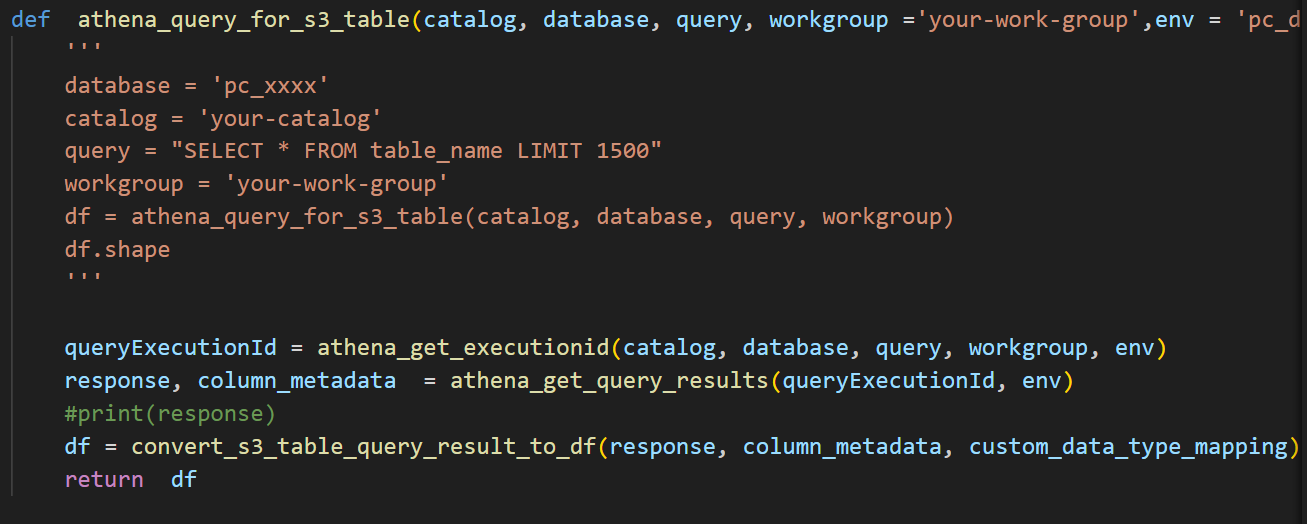
I am glad it finally works out although there are some difficulties. If you would like to follow along. The python file is here
thanks
Wenlei