Ensemble Pipeline Model with Stacking
One could try different machine learning algorithms for a given data science project. When you have a few different models at hand, one way to further improve the performance is to perform a model ensemble.
There are a few different ways to perform the model ensemble. Sklearn has a good write out for this. For example, random forest is an example of bagging, while Xgboost is using a boosting method. Besides that, you can also do voting and stacking to ensemble.
Sklearn provides classes to help ensemble through voting and stacking. You can check the following links. They also have the regressor variants if your problem is regression.
https://scikit-learn.org/stable/modules/generated/sklearn.ensemble.VotingClassifier.html
https://scikit-learn.org/stable/modules/generated/sklearn.ensemble.StackingClassifier.html
On my hand, I have good luck with the Voting method. Notice that you will need to tune the weight of each model in voting, which you can do with Optuna.
However, the stacking method from Sklearn often results in worse performance. I did some reading on this topic. The following blog helps me.
- Steven Yu’s blog has a good overview of stacking and blending method.
- Jason Brownlee’s machinelearningmastery blog has end to end example.
- Anisotropic’s Kaggle post showed more detailed example.
If you read those posts, you will find the example Sklearn showed in their documentation is a highly simplifying version. You will need to implement Out-of-fold in your process to make the result consistent. The idea is very much like we use cross validation in hyperparam tuning.
I stole this image from Yu’s blog.
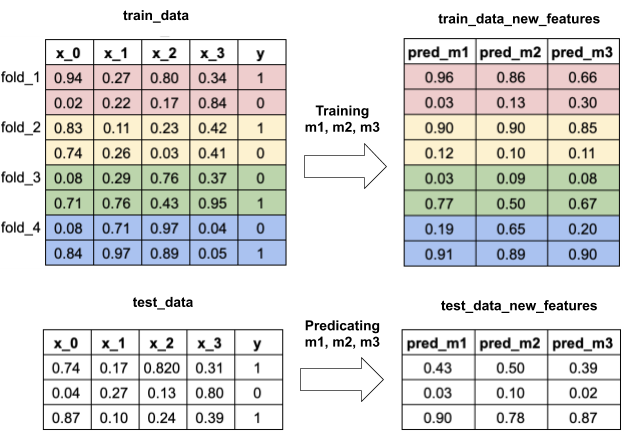
You can see train data were divided into groups like cross validation to produce prediction on the right and the results will be used to train 2nd level model, meta model.
Both Brownlee and Anisotropic manually implemented the “cross validation” data process through the numpy function. The following function is from Anistotropic’s post.

However, I got some trouble replicating the process as Anisotropic did because my process was using pipeline, one of which step was adding features like ratio et al (I call it pipeline model, but formal name is composite estimators per Sklearn). This requires some Pandas data manipulation. If I use the Numpy function to preprocess data into groups, I will lose the column name which will be needed in the adding features step. This broke my process. To mitigate that, I ended up altering the function to implement the same idea but made it compatible with dataframe (I believe majority people will need to preprocess the data before modeling, which is why we are using pipeline here).
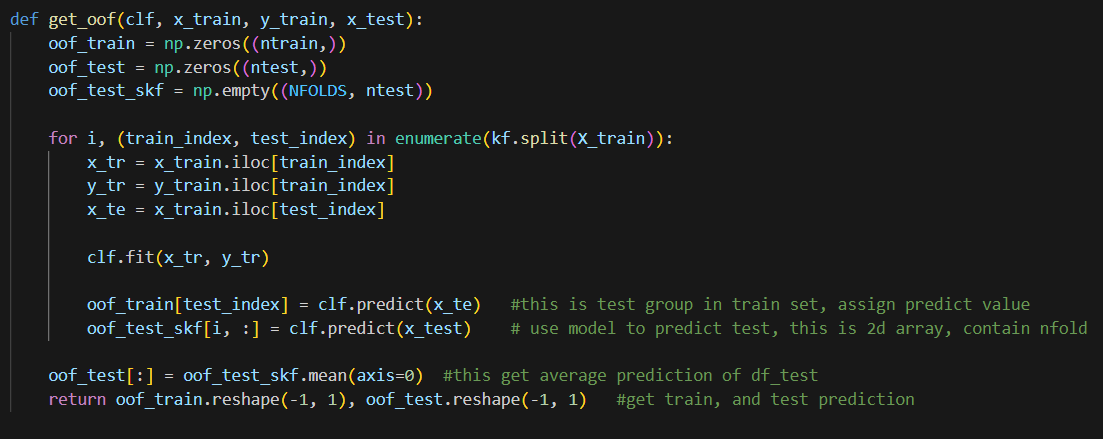
Notice I use .iloc here with the dataframe, so X_tr and X_te are still dataframes and can be used in the clf.fit function but keeping the column name. In my case, clf will be the pipeline model, this way I don’t need to make any changes on existing processes. Here I collected the prediction of the first level model.
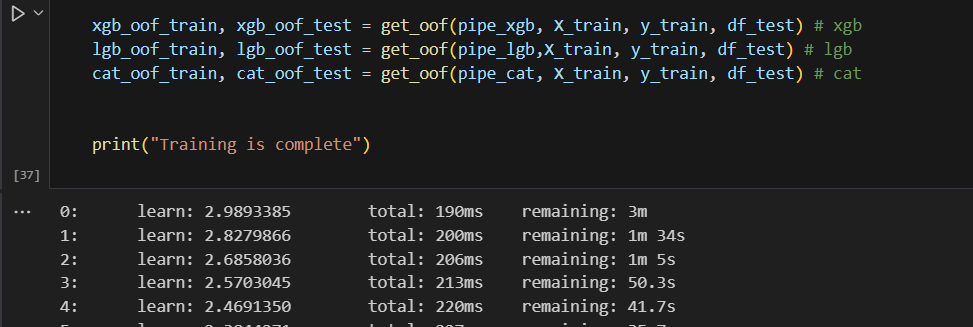
Merge together and form the dataset for next step.

with first level data, I used the Xgboost for my meta model.
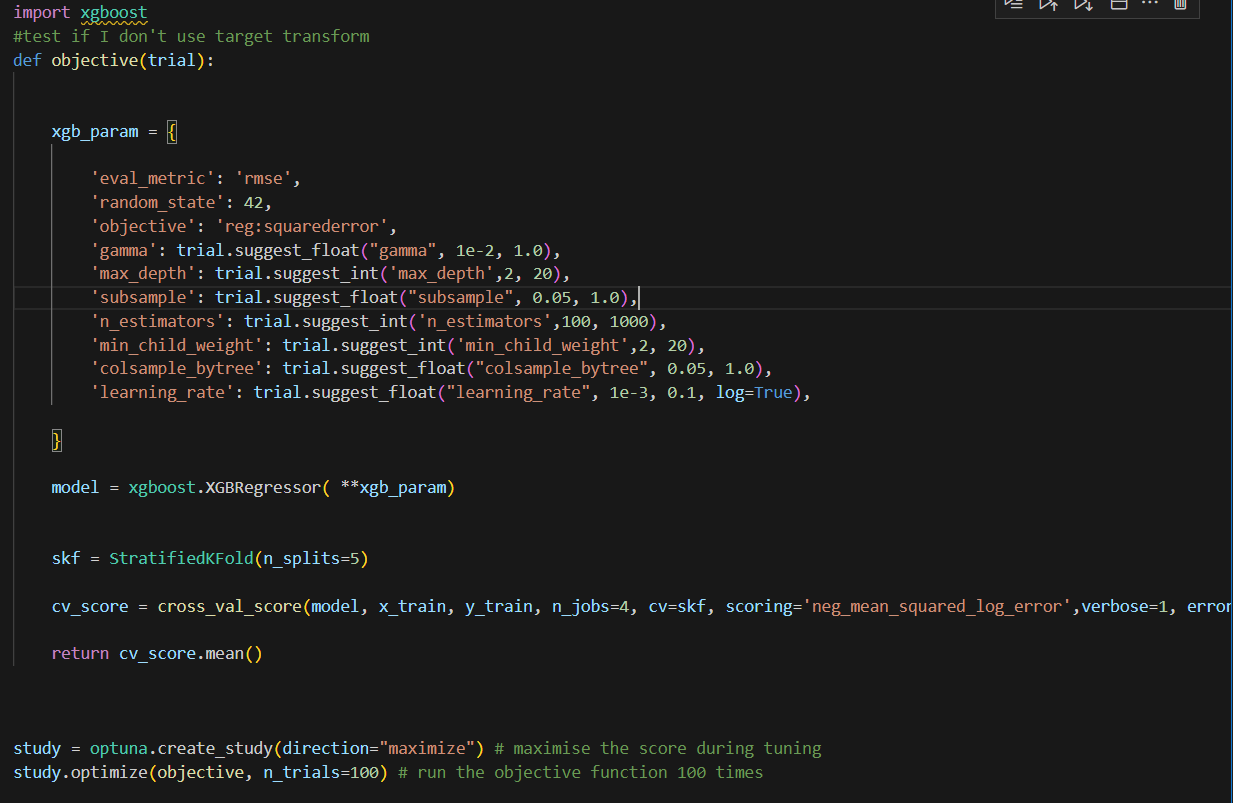
Here, Optuna was used to optimize the hyperparam of Xgboost and model performance will be compared under cross validation.
I was able to get the best params and use that for training and predicting the test dataset and performance did get improved. Please see the notebook here.
I hope this post is helpful for you.
Thank you for following along.
Wenlei