Example Using Table Partition in Incremental Loading
Many SQL Server database developers have heard of table partition. These technologies have been around for quite some time. But most people have never used it partially because people think they can make it do without it. However, If you work with large amounts of data such as a data warehouse or dealing with incremental loading. It is actually a very powerful tool should you know how to use it.
A real use case is as follows if I can redo it.
A couple of years ago, I had a post about how to let SSIS wait. Business scenario is that a table was used by a report. It took more than 30 min to copy data to the table. So ETL cannot take place until 7PM to avoid affecting user experience. The strategy I was using is to preload data in a staging table, create a SSIS timer. Set a logic if it is past 7PM, go ahead and load to the final table, if not, wait till 7PM to load. If I use table partition, I might not need to wait, I can just switch in to final table because there is no actual data move. It is only metadata change behind the scene. Therefore, the change is so fast that the user will almost not notice that.
There are quite some documentation and blogs about partition. These really help me to get started. I listed links which I think are great for beginners.
- This speaker is great and good primer to get you started
https://www.brentozar.com/archive/2013/01/sql-server-table-partitioning-tutorial-videos-and-scripts/
- Catherine shows different scenario and good examples to get your feet wet
https://www.cathrinewilhelmsen.net/table-partitioning-in-sql-server/
These links will give you enough knowledge to get started, but I found it is really hard to find an example code to do a batch incremental loading from a prospective of real work scenario.
The following is the first link I can get from google search about partition and incremental loading. This article is good but it is talking about high level concepts. It will not help you too much if you are going to work on bolts and nuts.
https://www.sqlservercentral.com/articles/loading-partitioned-table-incrementally-using-ssis
I decided to do some research to show how we can use table partition in incremental loading with a simple example. This will serve a starting point. With that, we can build more complicated solution. Here I am just using 1 or 2 records in a partition, but the concept applies if you use millions of records.
Let us make a fake table to carry out some experiments.
Wait, But before that, we need to create partition function, partition function defines what column you are going to use divide the table. It depends on your business scenario. If you compare data year by year, might be it makes more sense you create partition based on record year. Here we use ETLid as partition column You need to choose range left or right, it is confusing concept. Assuming you only define one partition column value 1, it divide column value below and above 1. You might ask what if column value happen to be 1. Here the left and right kick in, when you choose left, 1 will be grouped with number less than 1, thinking of the axis when you learn math in elementary school. If you choose right, 1 will group with number larger than 1.
If I still did not make it clear, I believe this Microsoft page explain better. https://docs.microsoft.com/en-us/sql/t-sql/statements/create-partition-function-transact-sql?view=sql-server-ver15
You also need to create a partition scheme. Partition scheme maps your partitions to file groups. You can define N partitions map to N file groups. But you can also map all partitios to one file group. For simplicity, I map all partitions to primary.
Here we create a partition function, which has two values. It will divide this column’s value space into <=1, >1 but <=2, >2. We create a partition scheme using the partiton fuction we just created.
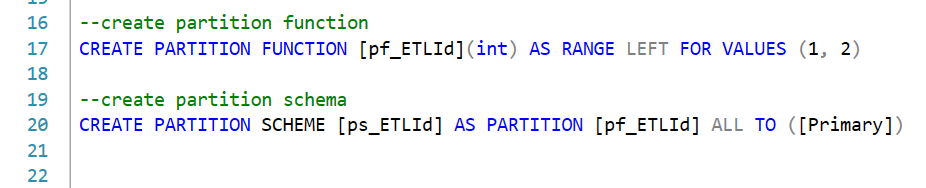
We created a table which contains columns and primary key (PK). Notice I use partition scheme twice, one is for the PK, the other is for the table. Also, the PK contained the ETLid, which is not usually we do when we create PK in a table. But it is necessary if you are going to do partition switch. Please check this post and read the comment part of the first answer.
https://dba.stackexchange.com/questions/20603/does-the-partition-key-also-have-to-be-part-of-the-primary-key
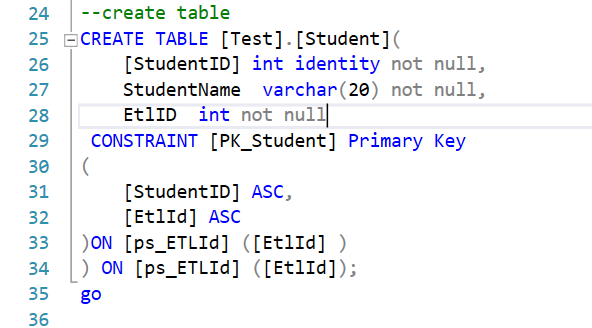
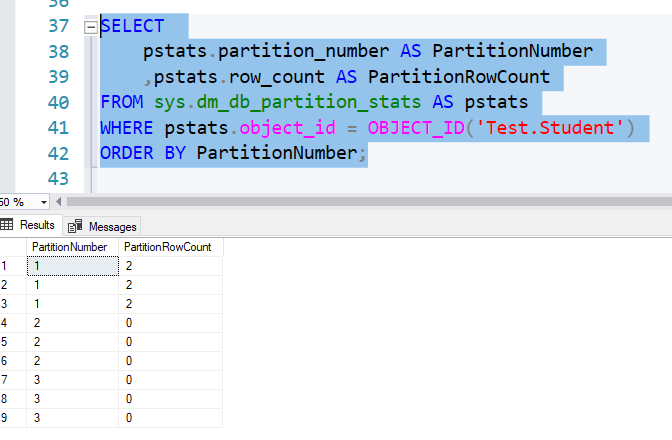
If at this moment we check the row number of each partition, it will be 0, but you will see 3 partitions as I have explained.
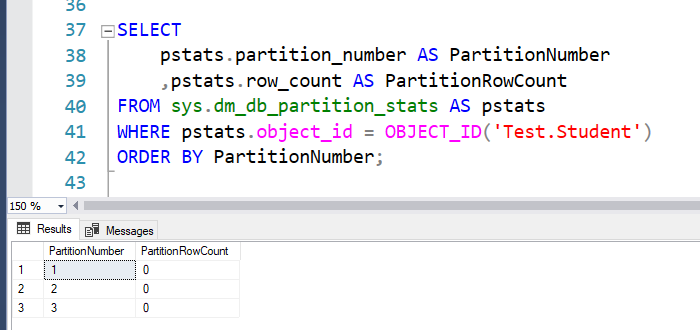
Let us add some noncluster index to the table to simulate real table, see what happens

If you recheck the row count, you will find two more copies. So these nonclustered indexes are partitioned as well.
Let us assume the table already contain some data, which is loaded by first ETL, ETLid=1
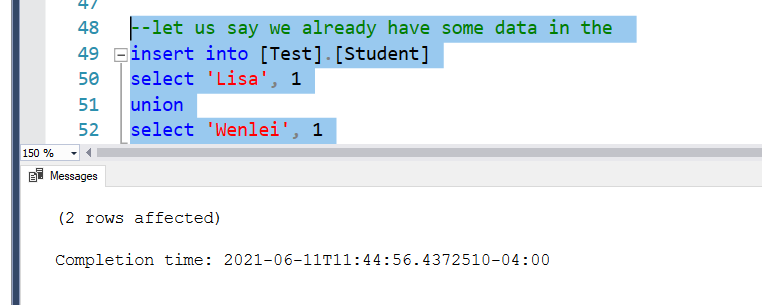
If you check the partition row count now, you will see first partition is loaded with 2 rows.
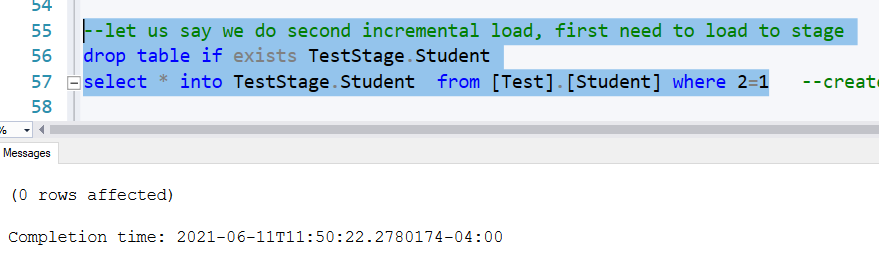
Now, let us say, we want to do second ETL ETL =2, Assuming we are doing a large amount of loading, so we load it to a stage table first.
We create a stage table using the existing table as template, but not copy the content by using where 2=1
In order for data to switch from one table to another. You will need to meet certain conditions. This Microsoft link give a detail info.
https://docs.microsoft.com/en-us/previous-versions/sql/sql-server-2008-r2/ms191160(v=sql.105)?redirectedfrom=MSDN
For our purpose, I added the essential primary key and the check constraint. Check constraint is a must in the source if you want to do a partition switch. Notice I use ETLid =2, because it is second load and it will be switch to 2nd partition of final table.
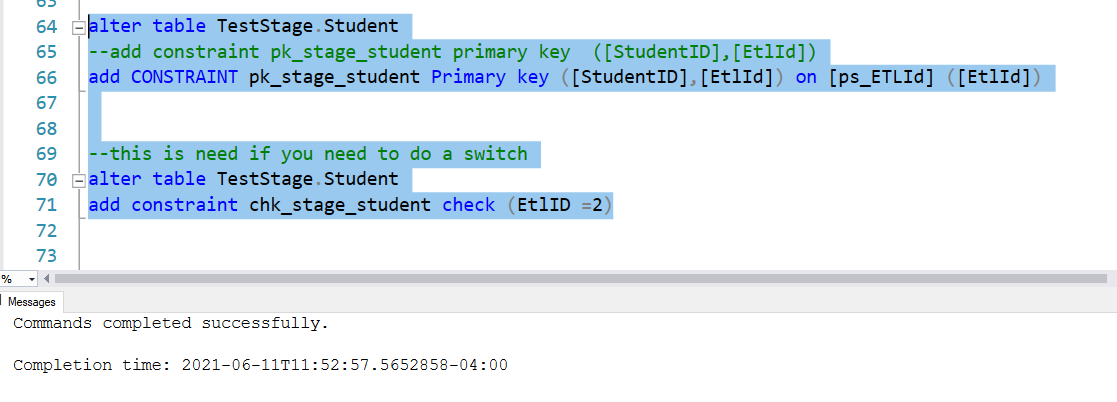
I will not add nonclustered index because it is not essential for partition switch, also if it is a big table, it is the best practice remove index so that loading speed will be better and add the index later.
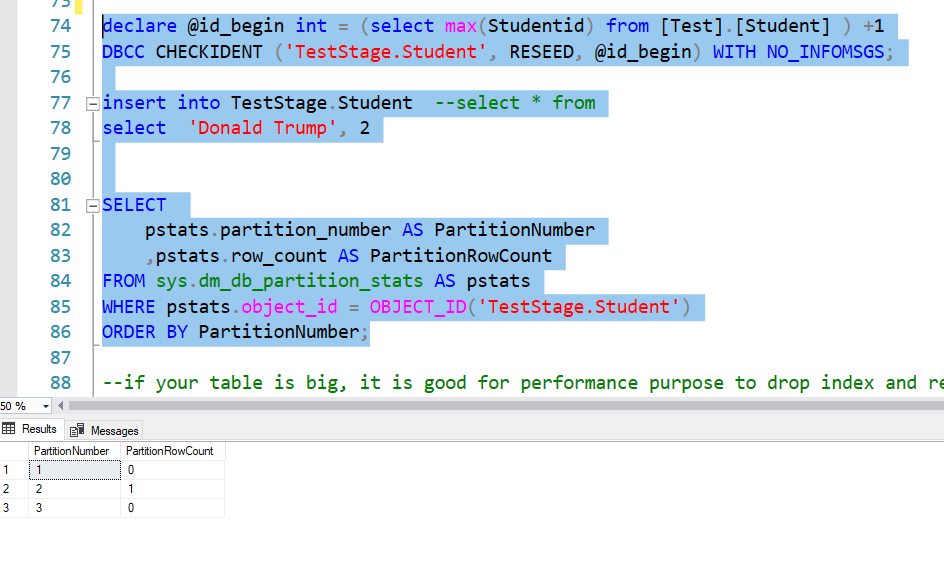
Row 75 is used to reset the identity column start value. Let us say your final table is already inserted 100 rows. You would start from 101 for studentid.
Now I insert one record in stage table, you can imaging I am inserting 1 million rows here 😊 .
Let us check what partition looks like, so you can see in partition 2, we have 1 row. That is what we expected. Next step is we need to switch this to final table
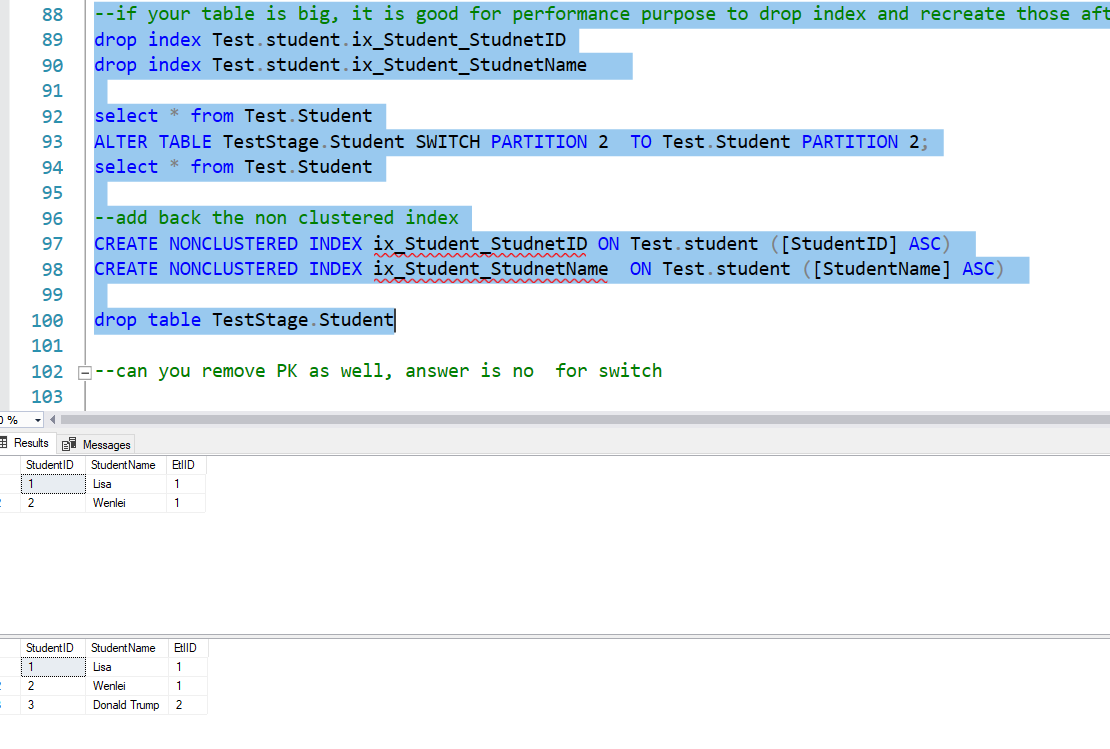
First, I drop nonlcustered index, so keep stage table and final table similar. Then I do switch.
We check data in final table before switch and after switch. You will see Donald Trump is appeared in the final table and in 2nd partition. Imaging a large amount of data was moved in less than a millisecond, this is great for ETL developer. Finally, I drop stage table, since it is empty now.
Now what if we need to do the third ETL. We only defined 2 values in partition function, right?
We can use row 107 to 109 to move point to next partition, also add partition 3 to existed function. Next, when we check, you will see one partition has been added
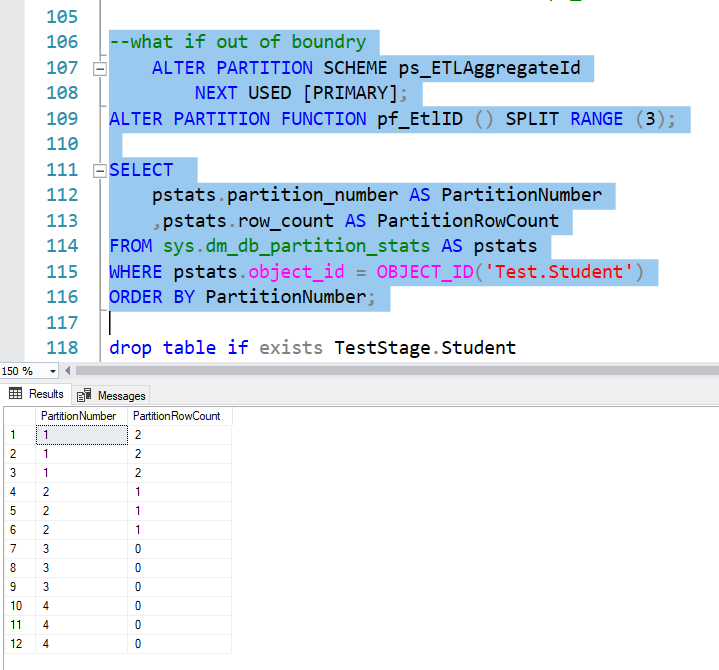
You can then repeat the incremental loading we did for partition 2. I don’t show the process here. But will include the code in the file.
This gives us the general idea how to do incremental using partitions in a simple example. This is a hard-coded / vanilla version of the script. How do we make it more powerful? You can use a dynamic script to achieve that. To do this for multiple tables, you can use the table name as a variable and build sql text and execute it. I believe if you are working on a partition, you probably already know dynamic sql. If not, there are a lot of resources online to read too.
Attached is the script I used in this demo.
I hope this help you understand the process of table partition and use that in your work.
thanks
Wenlei