How to Handle Textual Features along with Other Features in Machine Learning
When working on a real-life data science project. You will realize there are things you might not expect from what you learn in school.
- You spend the majority of your time working on data prep and data preprocessing.
- You will need to handle all kinds of data, not just numeric and categorical.
Scikit learn’s pipeline will greatly simplify the data prep and make it much easier that you can apply the exact same data prep logic to up-coming new data. But in real work, you often come across text type data, like notes, or social media text saved in the database. Those could be important features, which means you will have to use text mining techniques. People usually stay away from those due to challenges. It is a pity that we cannot take advantage of that, oftentimes then not, it could improve overall model performance.
Text is a bit trickier than other types of data in that you usually have to clean it and then vectorize it before it can be put into use. Other forms of dataset, like audio and image, which by default is already in a numpy array format. Therefore, those are relatively easier to incorporate than text.
Before I write this, I only see a blog discussing this. I would suggest people take a look since the author mentioned two different ways when you are using scikit and deep learning networks. One issue with the blog is the author did not provide a source dataset, so it is hard for readers to repeat the work.
Here, I would like to show how I go about it with an example via scikit learn framework.
I use Womens Clothing E-Commerce Reviews dataset. This dataset contain numeric, categorical and text field. You can download the dataset here to follow along.
First, we import all packages that will be used in the analysis.
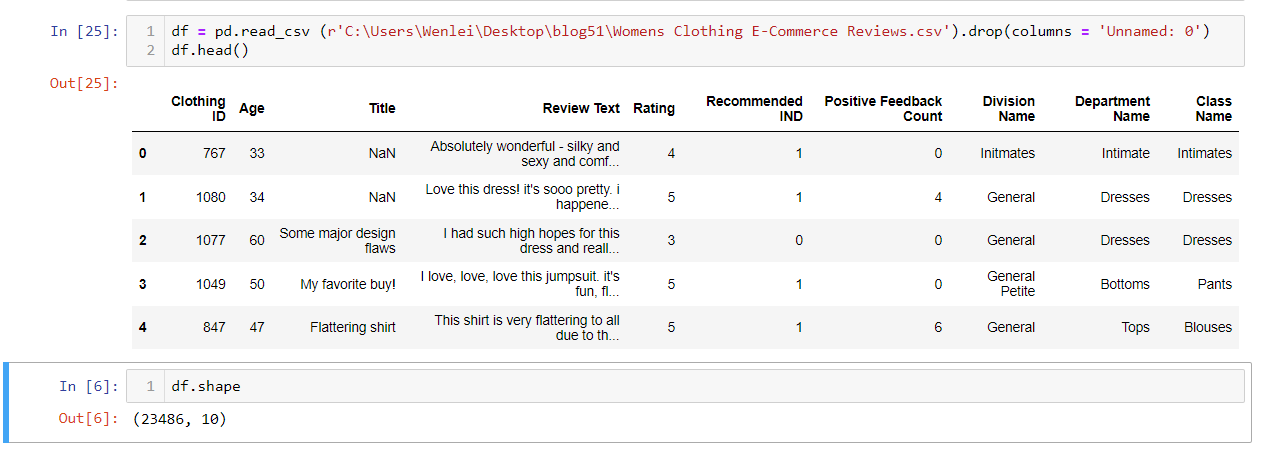
Now we import the dataset and take a peek at what the data looks like.
Using the info function, we notice data type and some missing data.
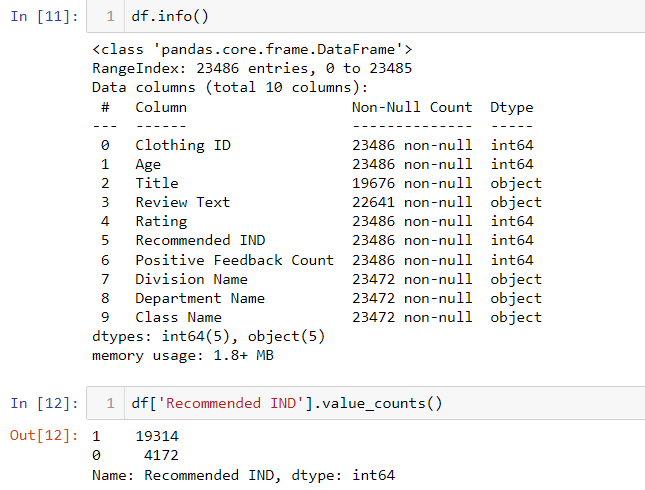
Among all columns, Review Text and Title are text columns. Also Recommended IND is an indicator used for the recommendation, which we will use as a binary classification target.
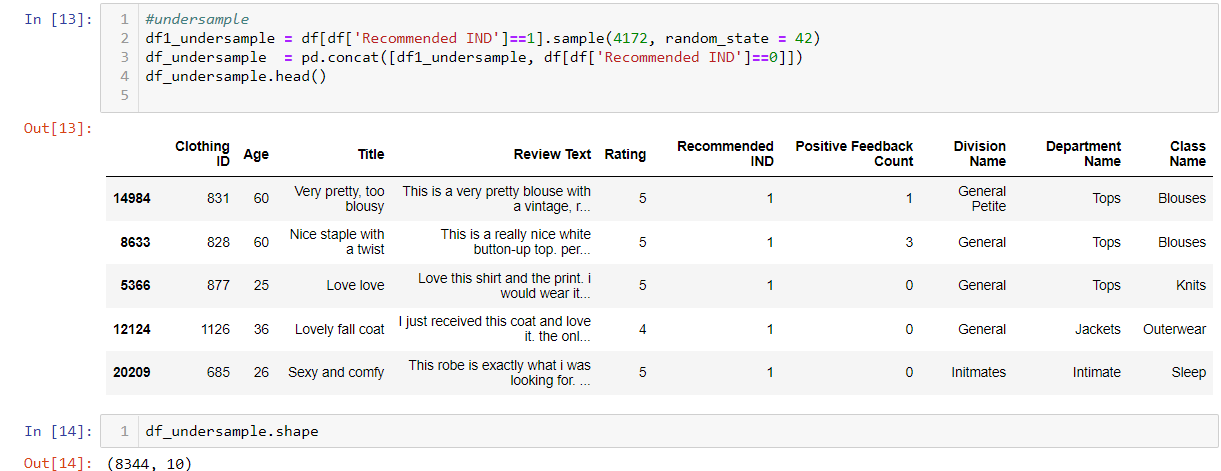
Besides that, it looks like the data is imbalanced data by checking Recommended IND value count in cell 12. In cell 13, I undersample value =1, so that I can create an equal number of positive and negative records in the dataset which will be used for training and test. It is very important to handle imbalanced data properly, otherwise, your model can learn to just predict the predominant value and still get high accuracy, which is not what you want.
You can use the python package, imblearn, to handle the imbalance problem, which will give you more flexibility. The following link will get you started. But this is not our goal here. So I used a simple step.
https://youtu.be/YMPMZmlH5Bo
https://youtu.be/OJedgzdipC0
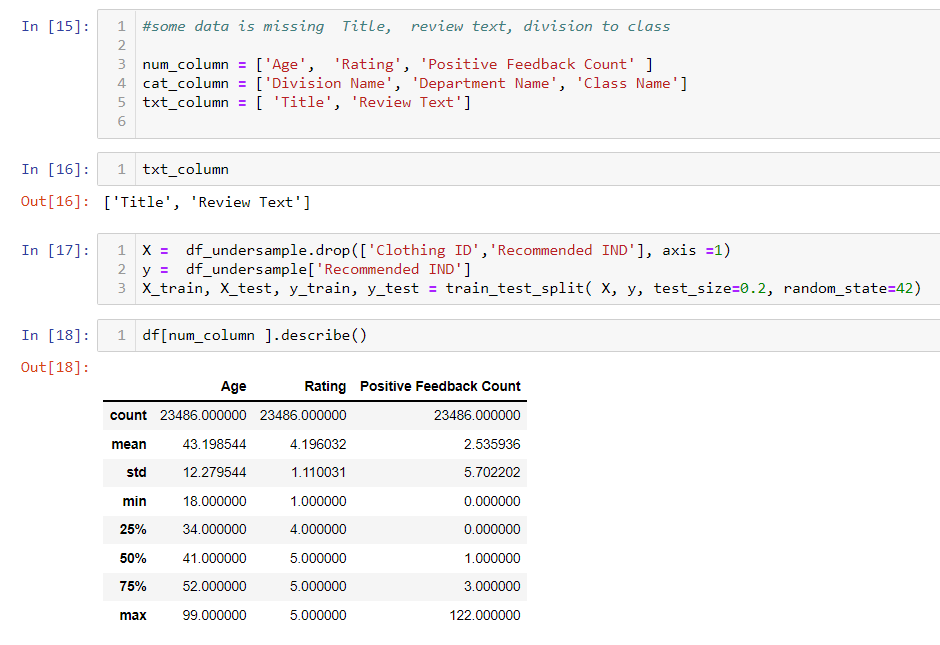
I defined column lists in cell 15.
I split the data into train and test in cell 17.
Since many machine learning algorithm only takes numpy array as input data, we will need to impute null, scale data, if data is not in normal form, we try to correct that, for categorical data, we will need encode it to numeric value, for text data, we will need to vectorize it.
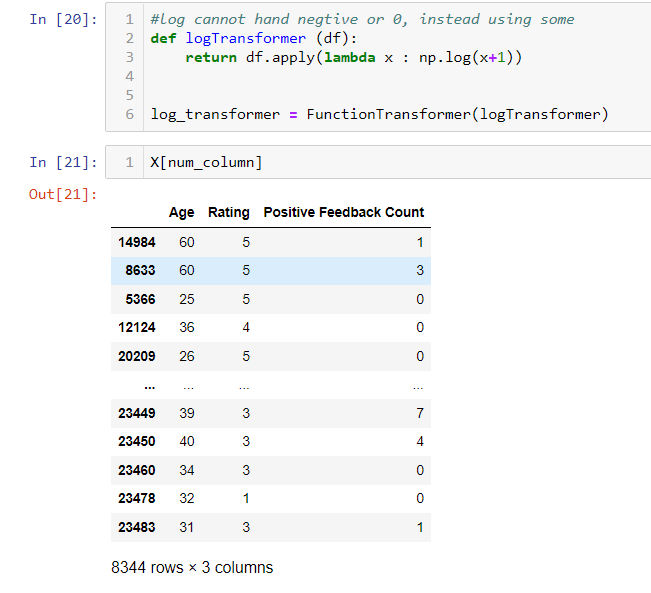
Next we will build pipeline for numeric data. Normally you will see an imputer and a scaler, we will add a custom transformer too. Since the data is not in a normal distribution. Let us try a log transoformation. Because there are some 0 values in the data, if we directly use the log function, it will generate –inf, which will cause trouble for the next transformation in the pipeline. Therefore, we add 1 to the original value, then do log transformation. In my case, the minimum value is 0, so it is fine. But if you have negative value, you might want to try other kind of transformation like box-cox.
In cell 20, I use functionTransformer to convert a function to a class. This is a shortcut in which you don’t have to write a class for a transformer.
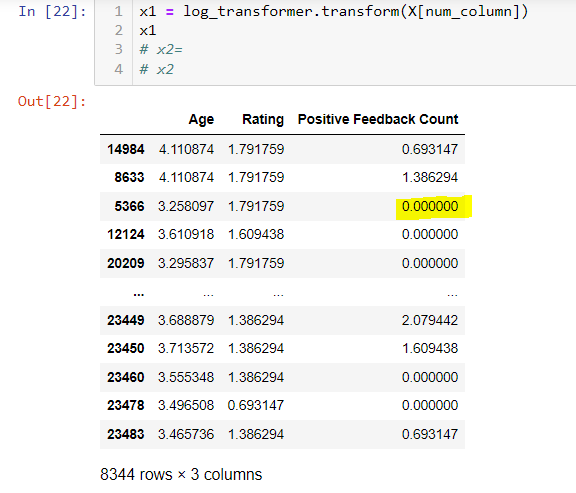
After transformation, notice the in third row (yellowshaded), the log(0+1) = 0, No –inf value anymore.
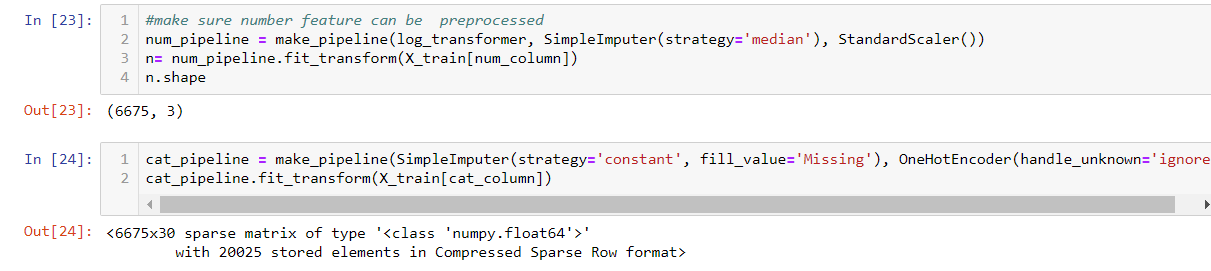
I use the make_pipeline function to create a pipeline. Here, I put the custom log_transformer into the pipeline. Then test both the numerical and categorical pipeline. Both work fine.
Next, I start to work on the text pipeline.
Since our focus is not training a model, rather handling heterozygous data. I will borrow Bert’s clean_text class to clean up the Review Text column. His blog is at the following address if you want to know more about clean_text function.
https://towardsdatascience.com/sentiment-analysis-with-text-mining-13dd2b33de27
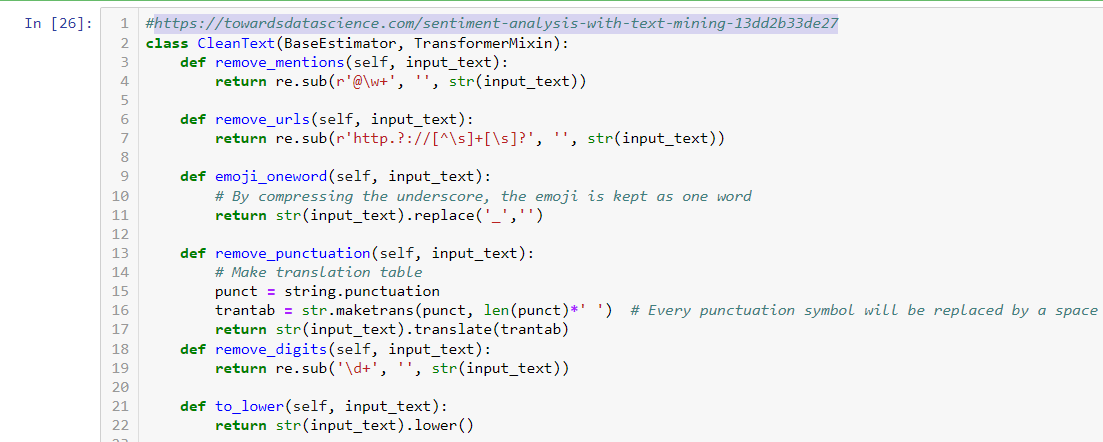
Both pipelines have similar components. Only difference, Txt2_pipeline contains clean_text step. Also, I chose to pick up top 100 important features vs 20, since review text is longer.
Let us give it a shot. Whoops! We get our first error in the txt1_pipeline.
This error tells us, our first step imputer needs 2 dimensional data, However we provide one dimension data. However, we have to flatten the structure with ravel function, because in the next step, countVectorizer expects one dimension data.
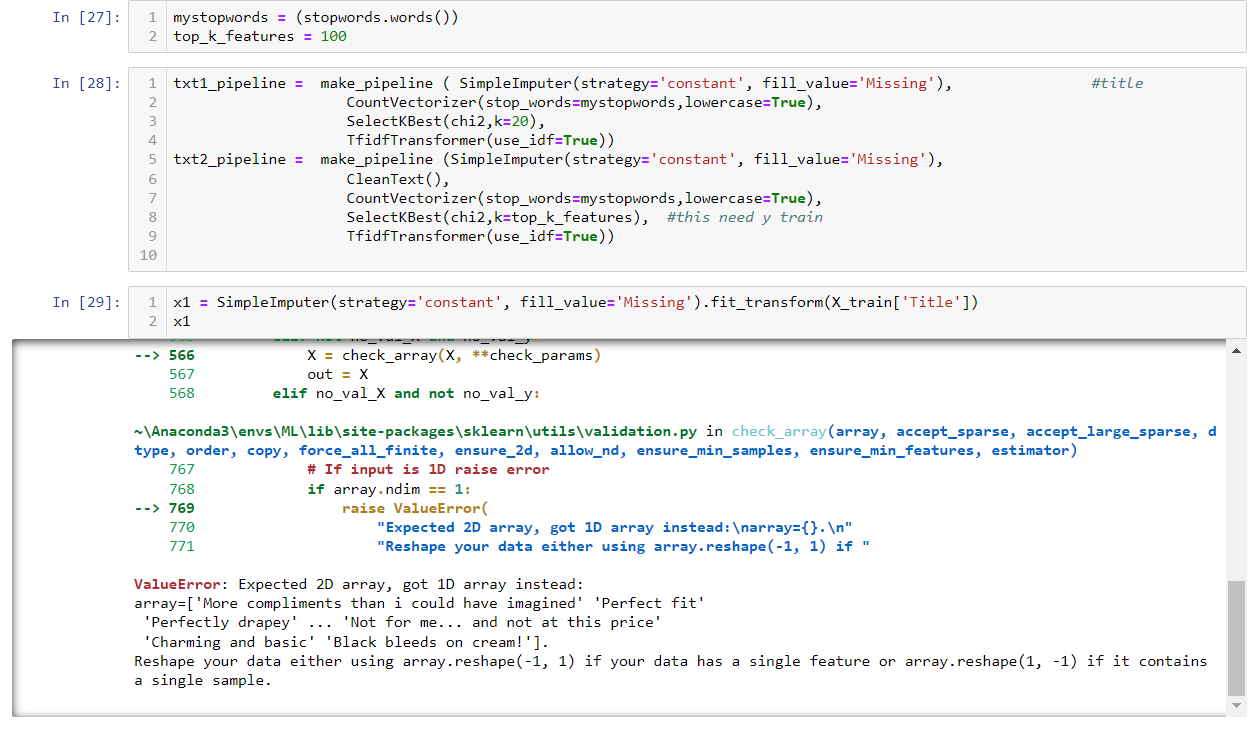
So, we need to fix that.
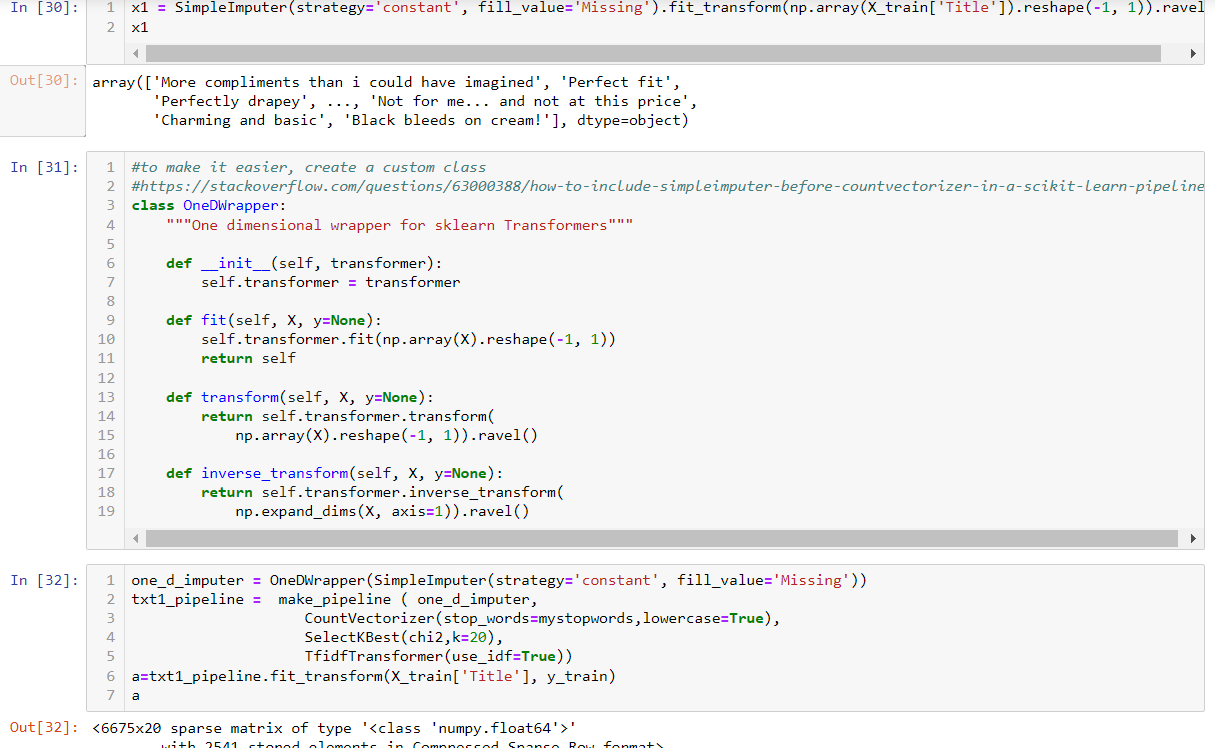
In cell 30, we reshape data for imputation. After that, we flatten the structure so that it is ready for CounterVectorizer. In order to use the same logic in the pipeline, This wrapper idea is good from stackoverflow site in cell 31. Once we wrap the SimpleImputer class, it will yield the correct format for the next step.
Same way, we can handle txt2_pipeline.
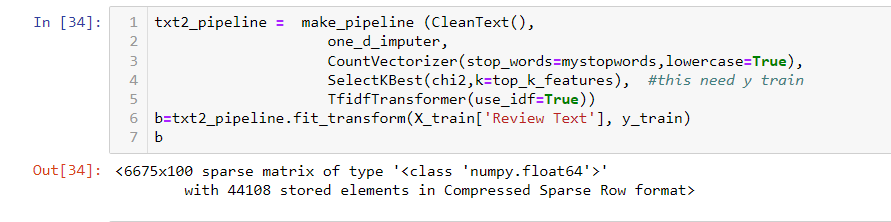
It is time to put those pipelines together. In cell 36, we can merge all these different pipelines together using make_column_transformer function. Here I came across the 2nd error, which is a bit weird. Since all previous pipelines work individually, I don’t expect there will be an error here. The error is the same as it is shown in this stackoverflow post. I have to change line 6 from [‘Review Text’] to ‘Review Text’ . This puzzled me about why the same error did not show up for txt1.pipeline. So far, I have no explanation but if you know, you can leave it in the comment section. The preprocess is successful, you can see that from dimension.
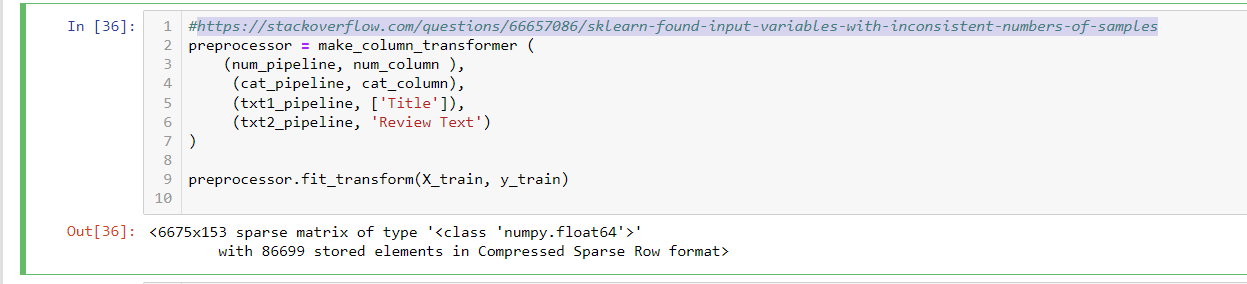
I put together a list of classifiers and params (part of screen). I included 8 different classifier to compare which one perform better.
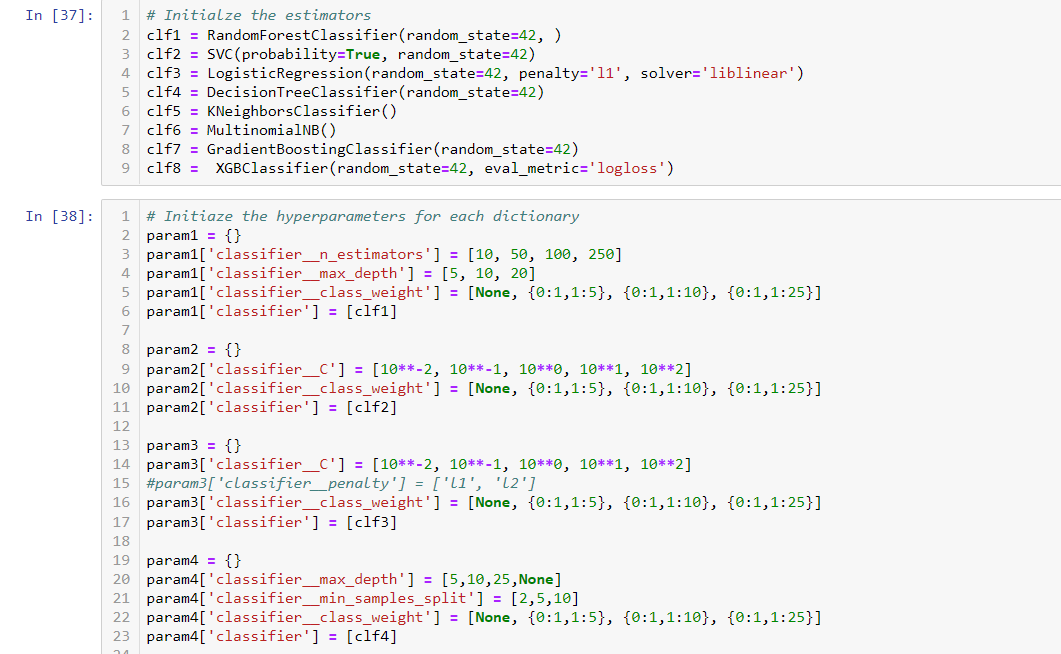
Now, in cell 39, we created a final pipeline with a classifier. And in cell 40, we did a RandomizedSearchCV to save time with 100 iterations, as our goal is not how good the model is. We are looking to handle textual features with others. The train is completed in 42 min.

I would expect xgboost did a better job, but here logistic regression won the gold medal, and xgboost is in 2nd place.
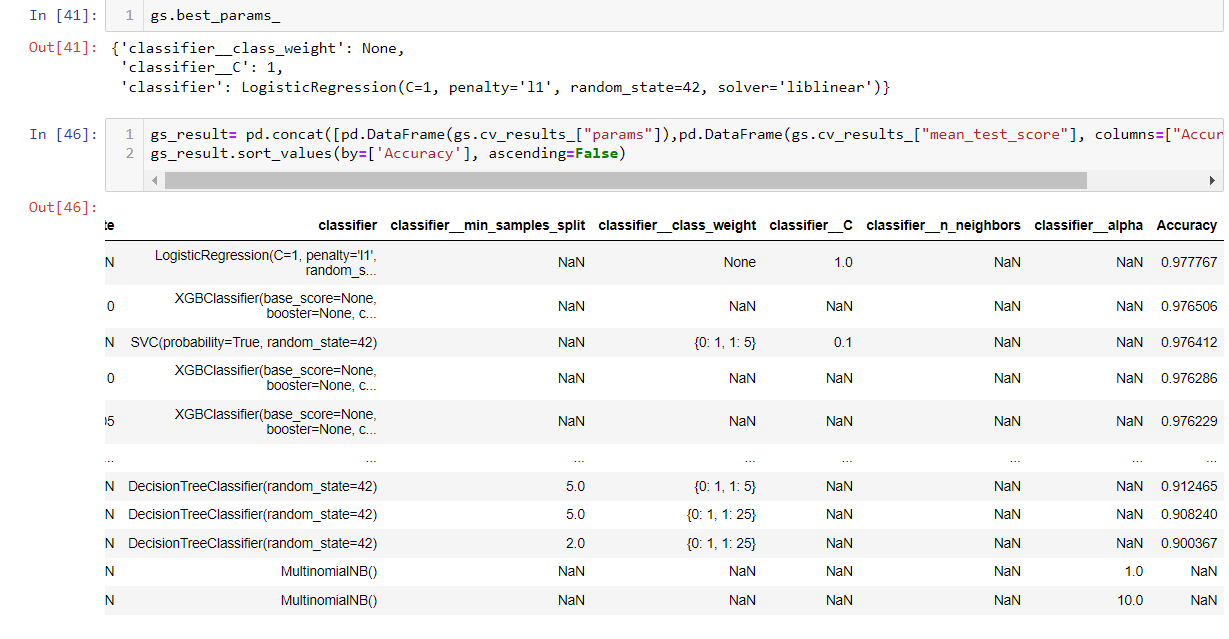
Let us see how it performed on test data it has never seen.
Looks like they performed pretty well. Both recall and precision are high.
I introduced some custom steps to simulate what you would encounter in real life. I hope you feel this is useful.
Some errors I experienced may have something to do with scikit learn design. But I wish this post could help you avoid some of the pains I had.
Thanks, you can download the notebook here.
Wenlei