Observe SAP data service CDC behavior using Table Comparison Transform
Change data capture (CDC) is very important for ETL developer. It is the foundation of data incremental loading. A lot of companies now require data to be refreshed on the daily basis. If full load of ETL process takes less than 24 hours, you can still manage to do it with full load daily. As source data is growing, the full load cannot be finished within 24 hours. Now, it is the time that CDC comes in to play.
In SAP data service, table comparison transform can be used to compare incoming data with existing data and further update the existing data. It has some configurations which might affect the outcome of CDC, I would like to use some dummy data to see different CDC behaviors so that we can understand the configuration and know when to use it.
Let us first create a customer info dummy table test_cdc_1, we use it as an existing table
 In this case, I have 3 persons and they have the address info listed in table. Now we want to see CDC’s three actions, insert, update, and delete. We design an incoming table, test_cdc_2. So we can see these 3 actions.
In this case, I have 3 persons and they have the address info listed in table. Now we want to see CDC’s three actions, insert, update, and delete. We design an incoming table, test_cdc_2. So we can see these 3 actions.
 In this table, you can see John keeps the same location, Kevin changed location to Cambridge, Lisa is not customer anymore. But we have new customer Mary. So John keep the same, Kevin will need to be updated, Lisa will be deleted and Mary will be inserted.
I created data service job like the follows, what is displayed is data flow part.
In this table, you can see John keeps the same location, Kevin changed location to Cambridge, Lisa is not customer anymore. But we have new customer Mary. So John keep the same, Kevin will need to be updated, Lisa will be deleted and Mary will be inserted.
I created data service job like the follows, what is displayed is data flow part.
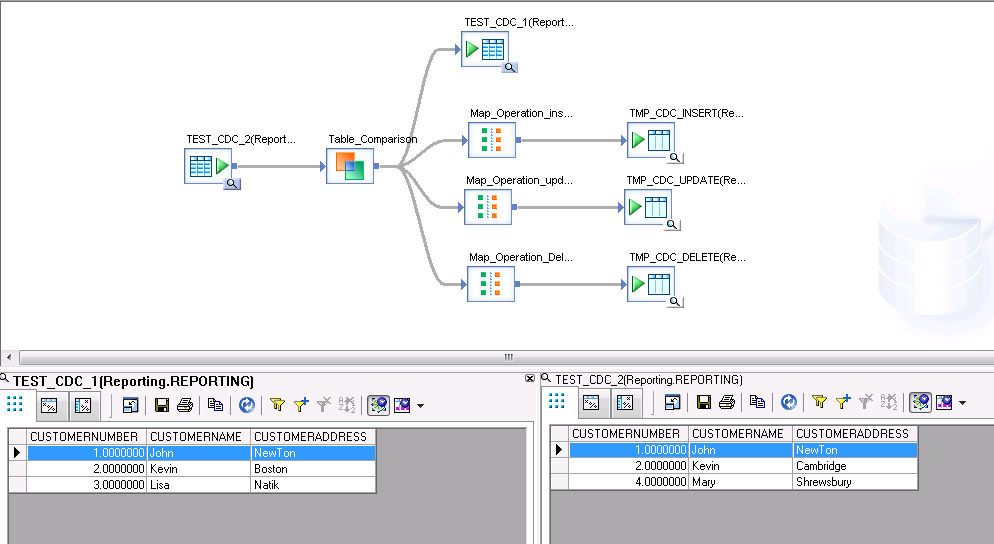
In this data flow, you can see the data before the job is run. I included three map operation transforms to collect the records, which defined by table comparison as insert, update and delete.
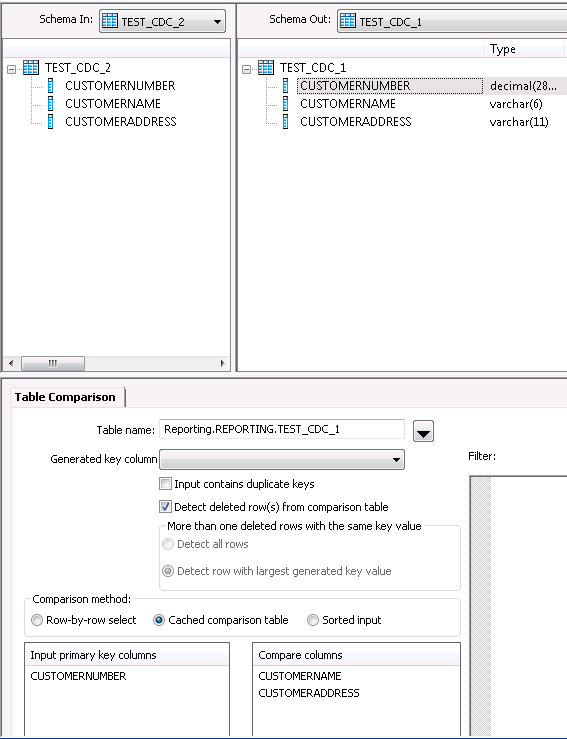
Double click the table comparison, we can see the configurations. You can see we are comparing two tables based on their customernumber and monitor the change of customername and address. Please note, I checked “Detected deleted row” options because I want to monitor what in deleted in existing table. If you don’t need, you can leave it unchecked.
After the job is run, we can see test_cdc_1 table data has changed as we expected.

In the real life, things are not always simple as that. Let us say, the same customer show multiple times in the incoming data. For e.g., Kevin has to move twice because he did not pay the rent. Mary is new customer, she also moved twice. Their names show twice in the table. How table comparison transform handles that?
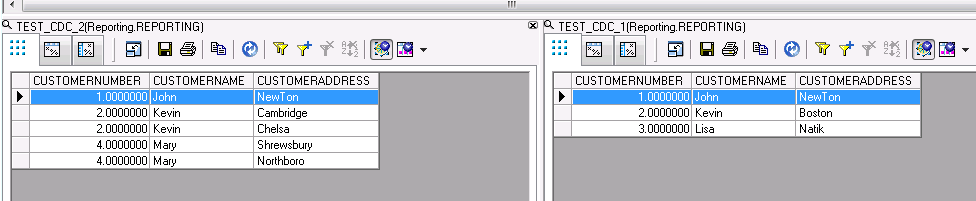
This is happened after I ran the data service job.

Kevin only get updated once, but it is not latest address. Mary has been inserted twice. This is not correct. Fortunately, Table comparison has an option we can choose.
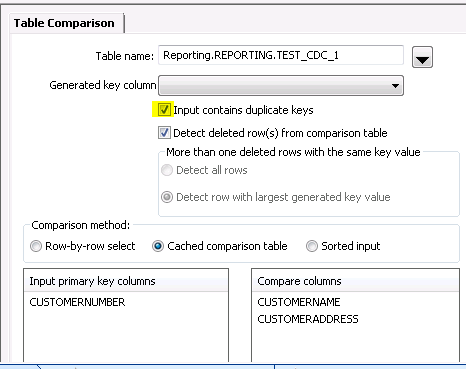
If we check this option, that means our incoming data could have multiple records for one customer. Let us see what happens if we redo the previous step with this option on.

You can see on the left side, the existing table has been updated with the most updated info. That is good.
Another scenario, what if your existing table has duplicate records for one customer. When you do incremental loading, what is going to happen?

In this case, Kevin shows twice in the existing table. The incoming data only has one record for each customer. This is after the job is run.

Notice, the duplicated one is replaced by only one record.
What if both side has duplications
Before

After

Notice that we expect kevin will be updated with Chelsa, but it did not. Check what actually recorded in the map operation. Insert records
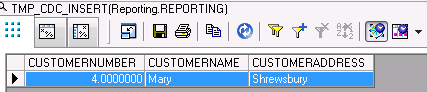
Update records
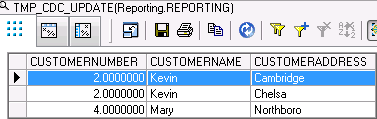
Delete records

You notice in update, Kevin does have two updates, but also in delete, you found chelsa is delete, which I don’t understand.
In summary, SAP table comparison transform is very robust tool. It can handle duplicate key issue in incoming data by turn on duplicate key options. For multiple key in both incoming and existing table, it has some unexpected results. Maybe I missed something here. Someone could point it out for me. I will appreciate.
As always, I have the SQL source code here for download.
Please note my backend system is oracle, so the syntax is orcal SQL. Also you might need to adjust the column length because table is create by dummy data. The length is defined by the longest one in the dummy table. If your new insert is longer than that, you will come across error.
thanks for staying with me for this long experiment. :)
Wenlei