Sklearn Pipeline Deep Dive
Whoever used the Sklearn pipeline knew how convenient it could be when handling train and test data.
In this post, I want to deep dive in the Sklearn pipeline. I will try to answer the following questions. I will answer with a minimal working example (MWE).
- By default, a Sklearn transformer will output a numpy (np) array for computation efficiency. Is this always the case in every transformer?
- How do we dynamically choose different columns for different pipelines in a column transformer?
- People have been complaining about the np array output, as the column names are gone, they cannot tell which is which. This could be important for feature importance analysis. Sklearn has an option to enable pandas output. But does it always work?
- What if you have to use np array output, are you stuck with the feature name?
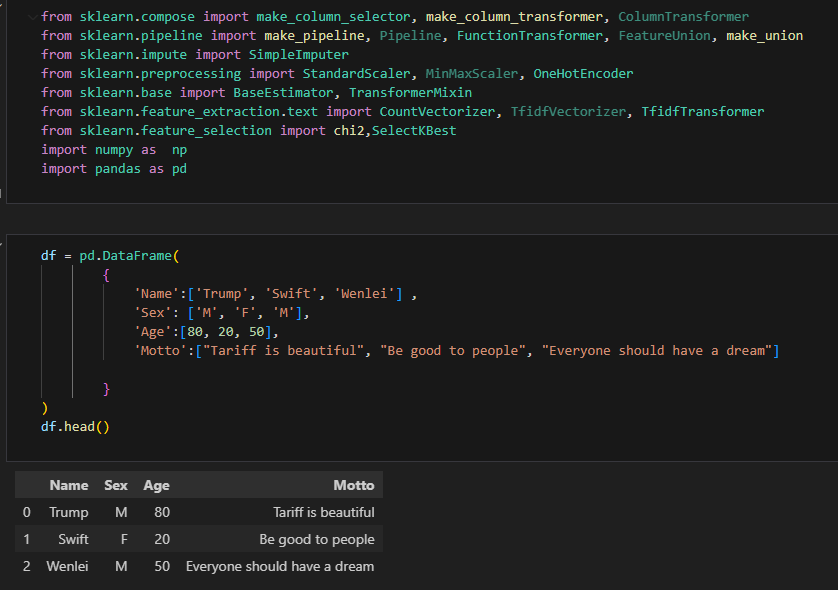
Let us first create a MWE. I imported all packages necessary and created a dataset containing 4 columns, two categorical, 1 numerical, 1 textual columns. Here I forgot to create a target. The values might be [‘president’, ‘celebrity’, ‘grass root’]. That might be a data scientist’s favorite. Today, we are mainly focusing on the pipeline. I will replace those with an arbitrary list when I need a target down the road. Please note here, I don’t set output = ‘pandas’. So, the transformer will output np.array by default.
Oftentimes than not, you will do some post extraction processes. That could be something you forget to do in previous steps. Or you could adjust something ad hoc. Here, I just created a function transformer to add 1 to the age. I will design the next step to use the age column by name.
![]()
I use the FunctionTransformer to convert the update_age function to a Sklearn transformer. It can fit_transform the dataframe I created previously and output a dataframe. Let us see if the next transformer can use this by column name.
![]()
I first defined the num_columns, cat_columns and txt_columns. Then I created a pipeline for each. Finally, I combined the num_columns and the cat_columns in the column transformer, where they went through different pathways. I then use make_pipeline to combine the function transformer with the column transformer. For sanity check, I first run the num_pipeline with the age column, it works. Now, I can run the whole pipeline using the original dataframe without specifying the column name.
This verified that not all transformers will output the numpy array. The exception includes custom function transformers, or you define a custom transformer whose output is a data frame. Sklearn transformers will output np.array like the cell 18 output. This is actually beneficial, because your custom transformers still keep column names for the next step to be used.
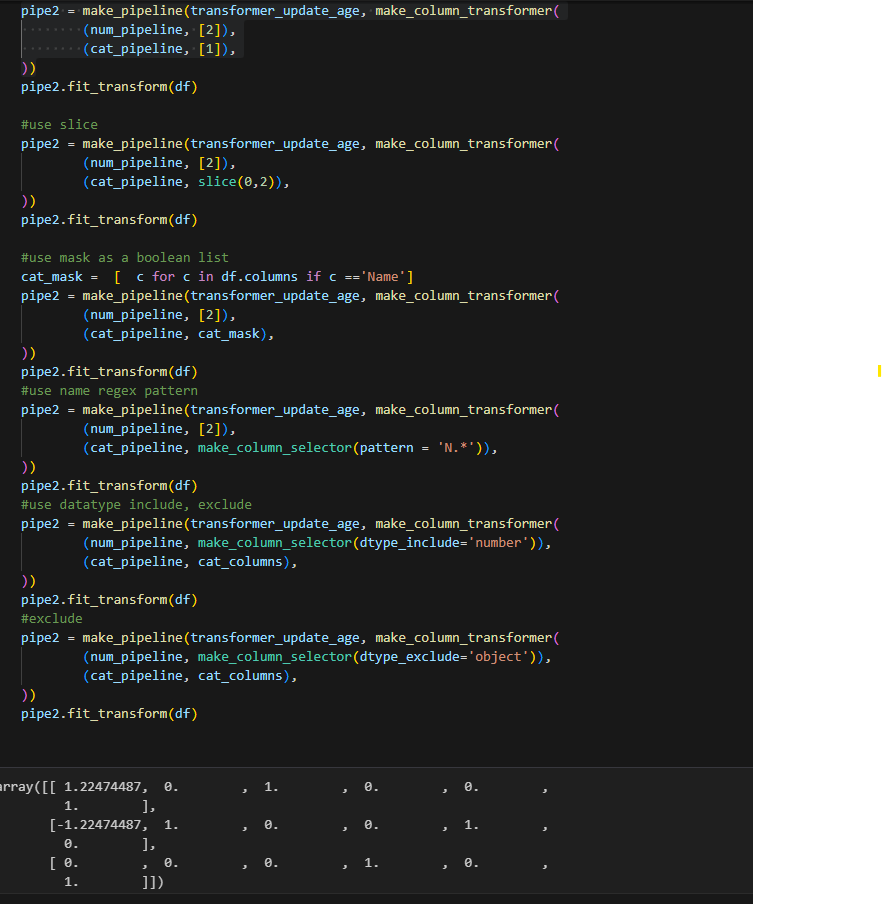
Most times, people define the column list for each pipeline like the last example. But when you have a large number of columns or your column list is dynamic such as you try to tune the model by choosing different features. You will likely use other column selection methods. There are mainly two types of ways you can do this.
- Use column index and its variants
a. Column index
b. Slice function to get column index, this is good if you know column range
c. Boolean list, you can use a function to create a mask, if there is logic - Use make_column_selector
a. Regex Pattern
b. Include dtypes
c. Exclude dtypes
These will pretty much cover what you need, but I will give you an example later that I still have issues with these options. You will have to think out of the box and solve the issue. That is part of the learning experience, isn’t it?
You might be curious that I did not add the textual column in. Textual columns are something special. If you build the same way like cat_pipeline, you will likely have errors.
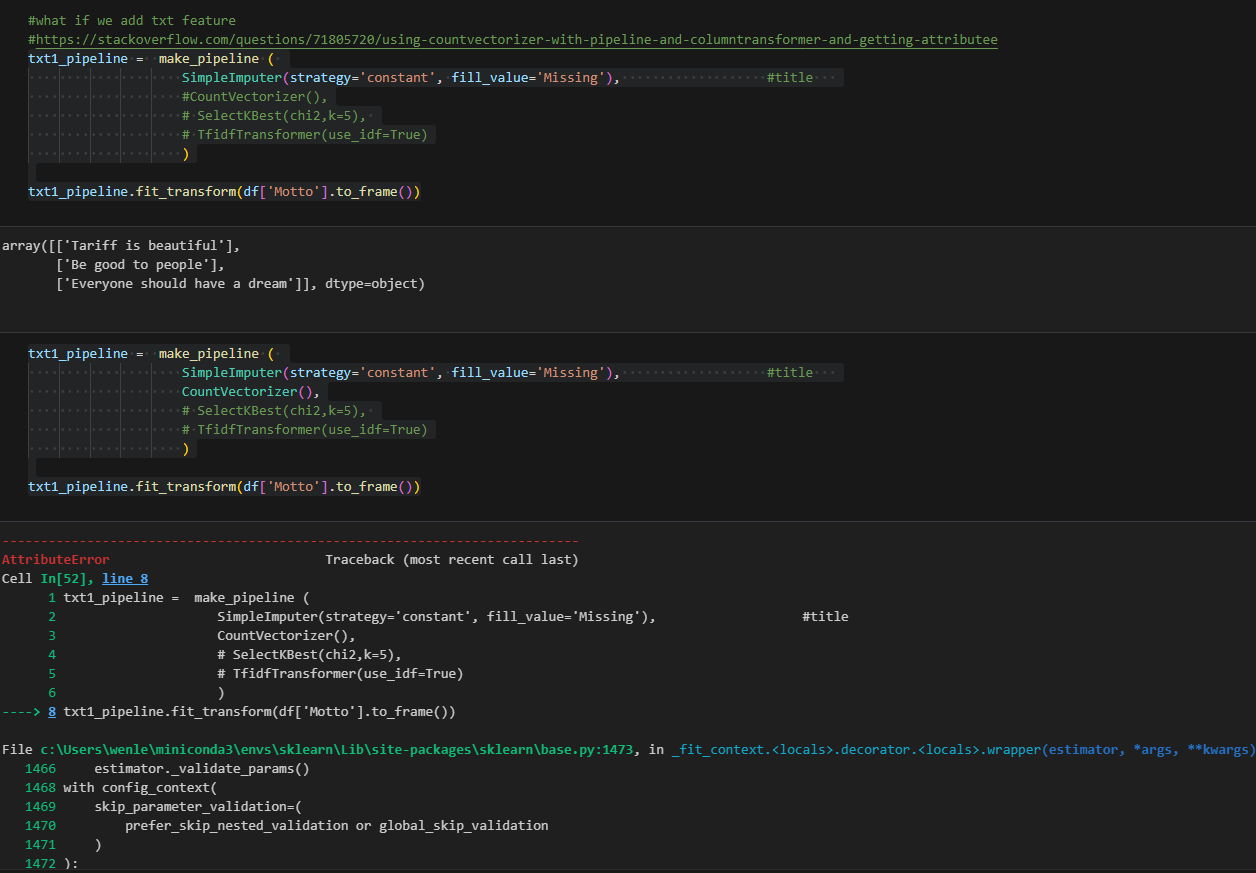
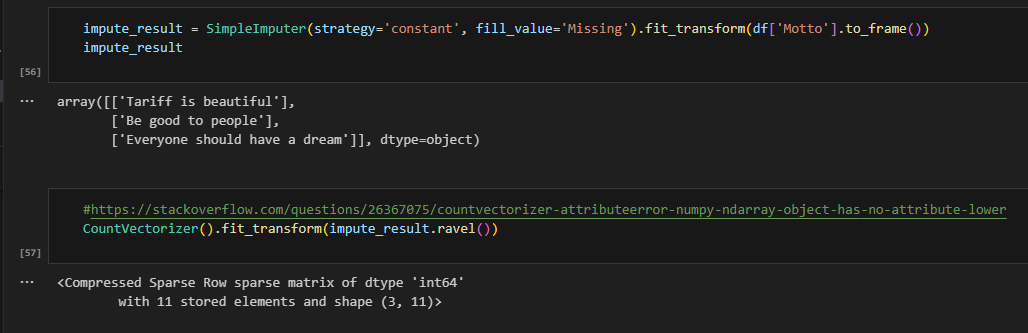
The error says “object has no attribute lower”, which is misleading. Because the SimpleImputer can process without issue, the output is a 2D array (see 2 brackets). The next transformer is CountVectorizer, which requires 1D structure. Here, I did an experiment. I first save the previous step in a variable, then make the array into 1D using the ravel function. It works after that. Therefore, all we need to do is convert the previous transformer into 1D and we can create a wrapper like so.
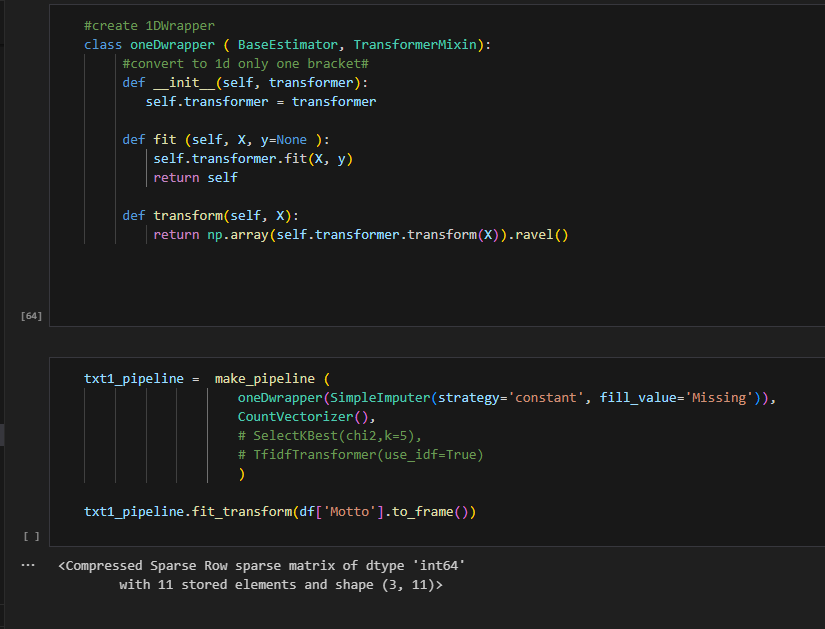
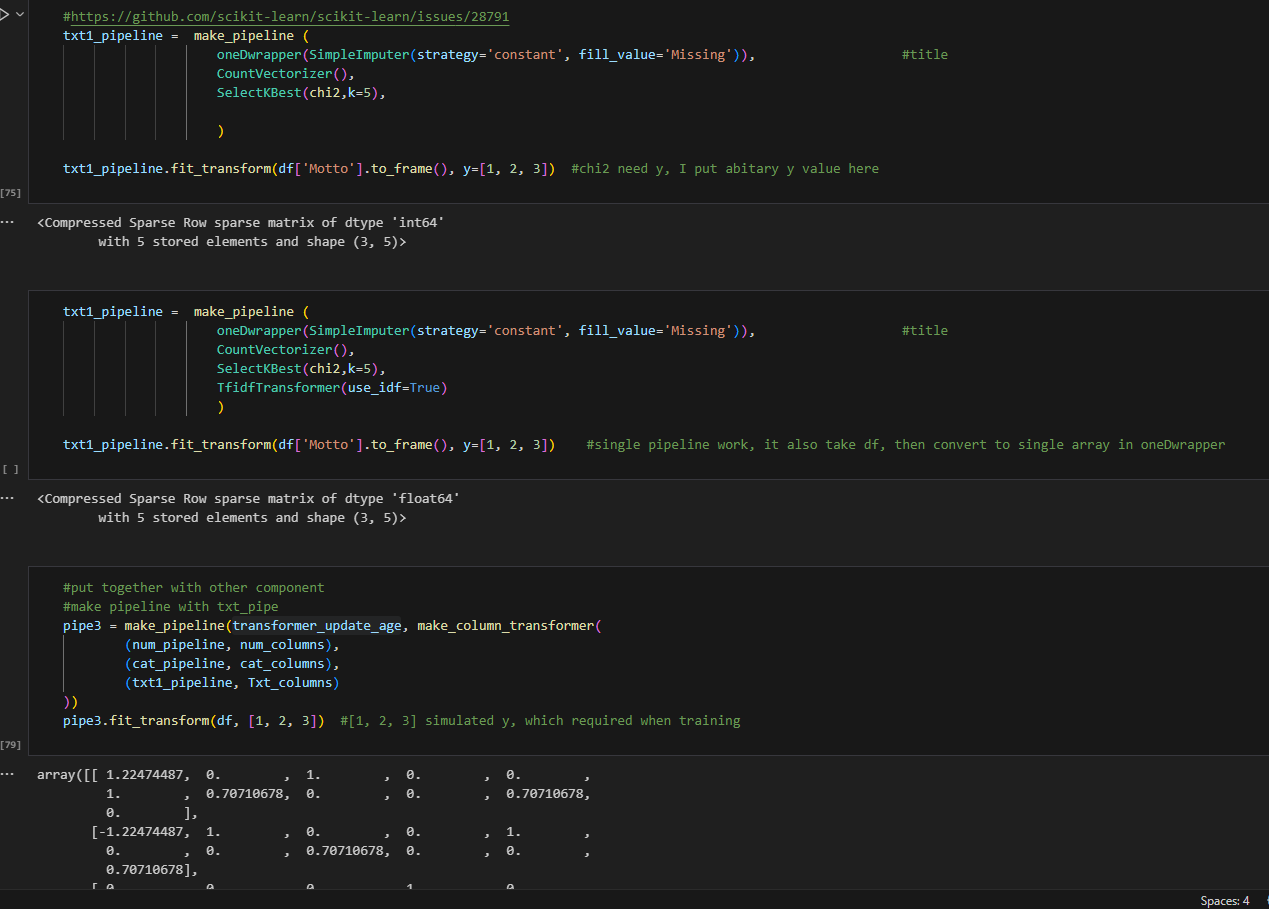
I further combined with other steps in the txt_pipeline, including the selectkbest and the tfidf transformer. Notice here, not all transformers need y. but SelectKBest using chi method will require it. I provide a fake target here (in real life, provide your real target here :) ). After that, I combined all three pipelines without issue. This NLP process is using np.array. Now, what happens if we set_output as pandas.
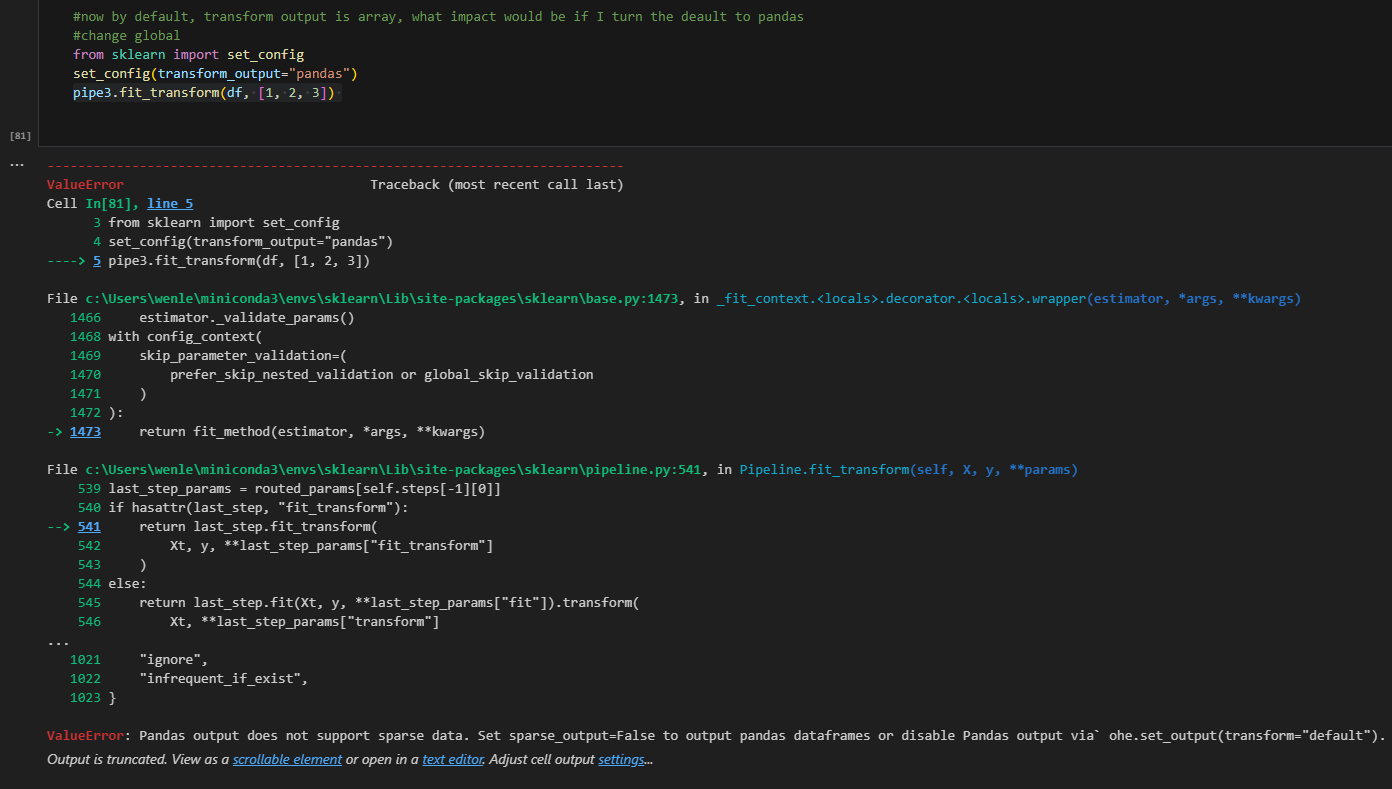
There are a couple of places that need to be fixed. But I don’t think it’s worth the effort. Especially for NLP, it only works with 1D, if you are using pandas output, by nature, it will be 2D. Therefore, my suggestion is just use default output if you are working on an NLP pipeline. So the answer for the previous question is that it does not always work with pandas output.
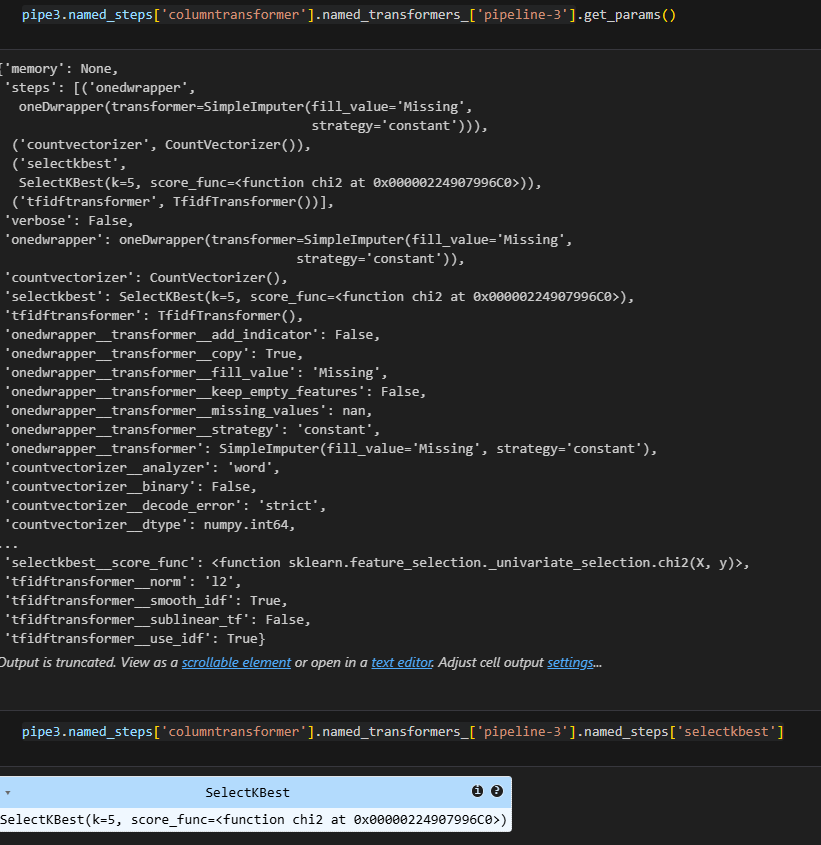
Given a pipeline which structure as follows.
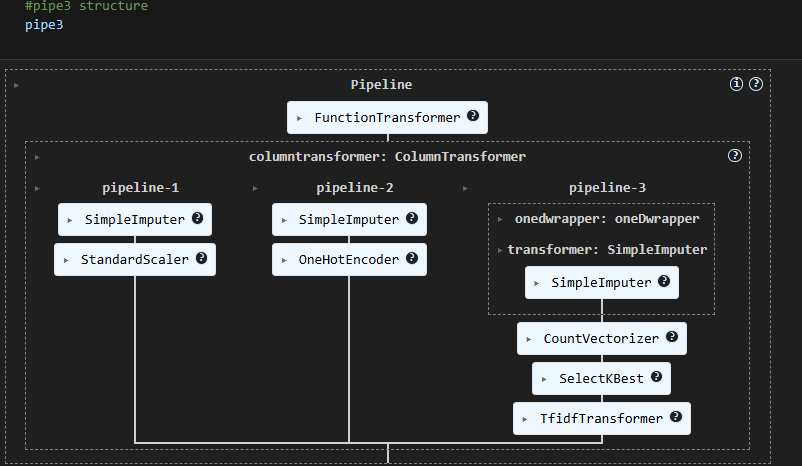
How do you get the final output feature name?
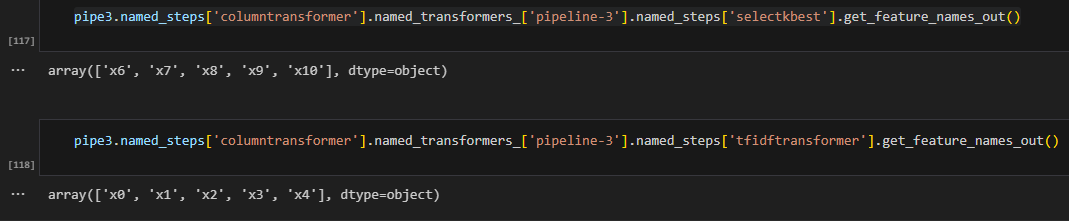
You will need to find the path to get there. The get_params () function is your friend. Notice pipeline use named_steps, transformer use named_transformer_. Once you find out the object path, you can use get_feature_names_out function to collect feature names. Therefore, you don’t have to convert it to pandas to get feature name. Since many features have converted into multiple columns due to one hot encoding, I suggest to use permutation feature importance to get feature importance in this case.
Sometimes, things could be more complex. For example, I try to dynamically choose features while performance tuning a model. Now, I would like the text feature to always be selected, but other categorical features can be optional.
The tricky part is both text feature and categorical feature are object dtypes. So you cannot use make_column_selector to choose. One option is you can rename the column, for example, adding txt_ prefix to text features, add cat_ to categorical features and then use regex pattern to do selection. But it seems cumbersome to change each column’s name. Do we have a better way?
Since we cannot tell them by data type. Can we select text features into one group and other features into another group, process it and then merge it afterwards. We will need to use the feature union method to do it. In order to use feature union, you will need to select columns first, which column transformer does not need to do that step. That is the difference between them. Here I have created a custom transformer to do that.
![]()
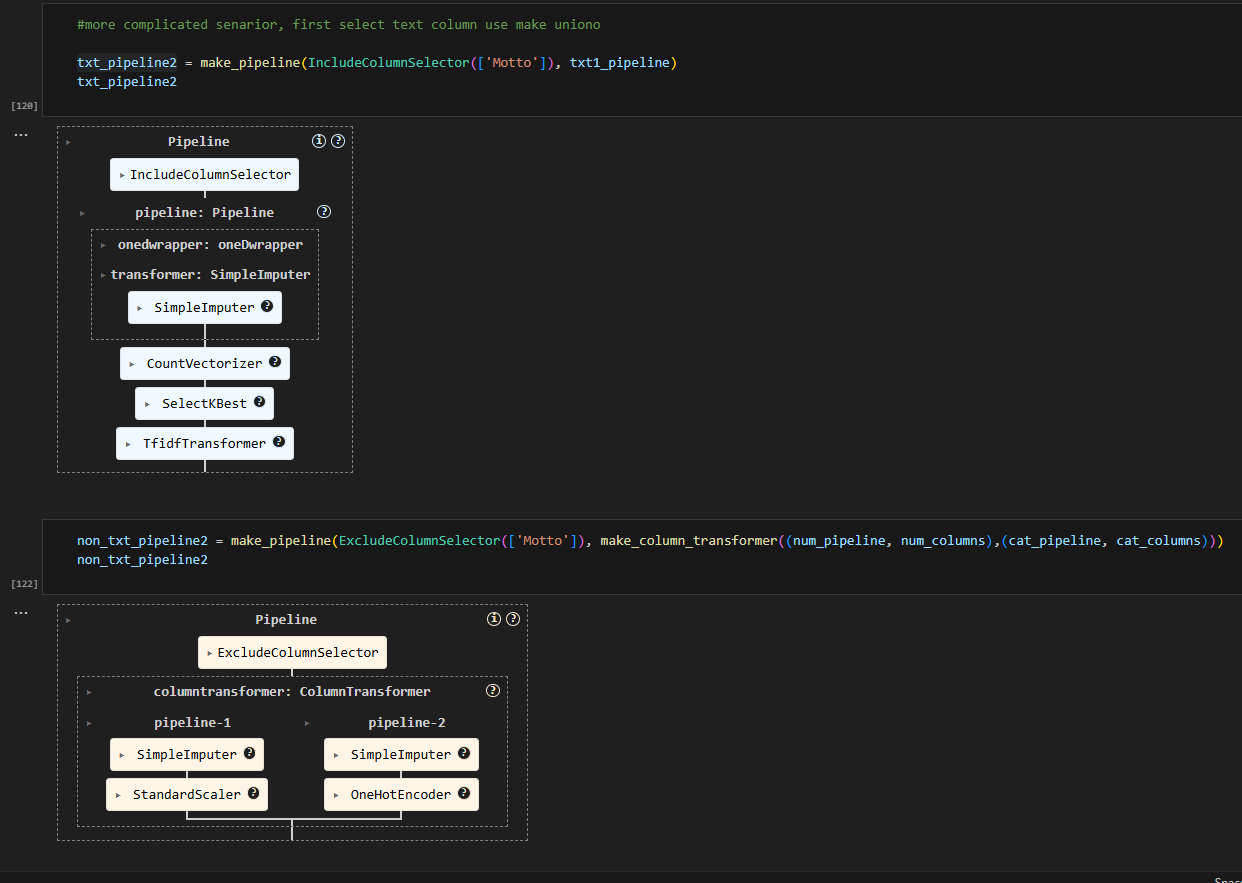
So I created a txt_pipeline and a non_txt_pipeline first. Because they are separate, you can now change the cat_column to use make_column_selector (include_dtype = ‘object’). It will take any object column.
Finally, I use make union and make pipeline to create a full pipeline and it works!!
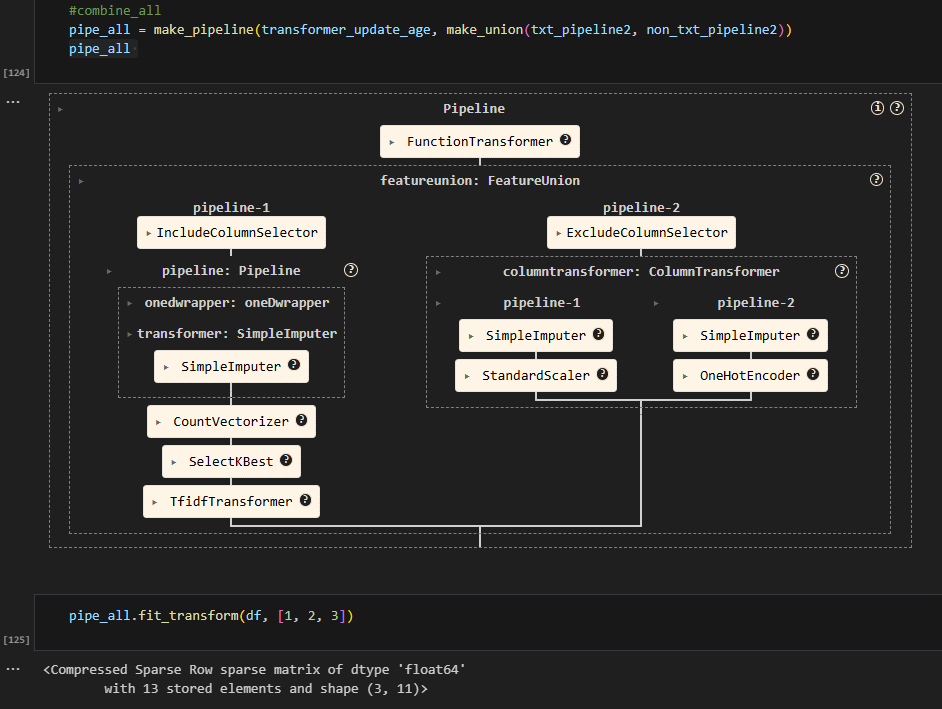
It is a long post. Hope you get something useful.
Happy Summer!
Wait, did I almost forget? You can download juypter notebook here
Wenlei