Entitle the Custom Transformer a Memory in Python
Before data can be used in machine learning, it will need to be preprocessed. Many machine learning algorithms cannot handle null and outlier well. So, these steps are important. Sklearn has a preprocessing class to help you do that. But oftentimes, something like capping outliers, using log function to transform the data, which requires you to write your own transformer class.
Let us say, when training your model, you capped the outlier with a 99th percentile value of training data. Now, you start to use the model to predict, your testing data also has outliers, should you capped it with 99th percentile of training data or testing data? Because your model’s params were built with training data. If you want the model to work properly, you would treat the test data the same as the training data by using 99th percentile of training data.
This means we will have to “remember” the training data 99th percentile value. This might not be a problem for 1 or 2 features. But what If you need to work on a model with 100 features. Thirty of 100 features need to be preprocessed with the 99th percentile value. How do you track all those numbers? It is not practical to remember those values and hard-code those in function. Let us see how we can use class to track those for us.
In addition, there are times that we need to preprocess data separately and then feed to the model hosted somewhere else. A custom transformer class can preprocess data in one step. Besides that, you can store the fitted transformer physically somewhere and reload it only when you need to. That is convenient for lazy people like me. I will show how it works as well.
Let us see how a custom class can help us with that.
First, let me show non class version
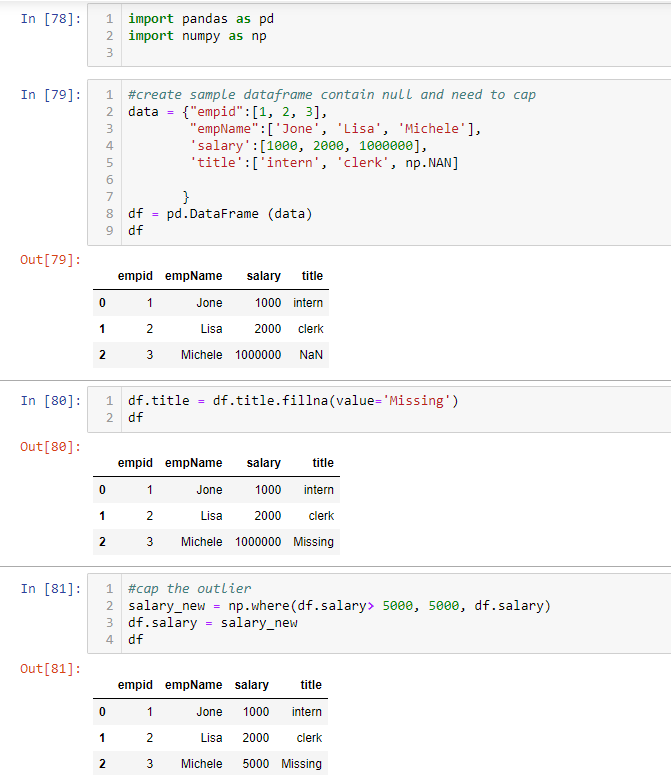
Cell 79 creates a data frame from a tuple. Notice I introduce an outlier in row 4 and a null value in row 5. You can fill null value and cap the outlier in cell 80 and 81 (hard coded for simplicity)
Now,the hard code method works, let us see how class can simplify our work.
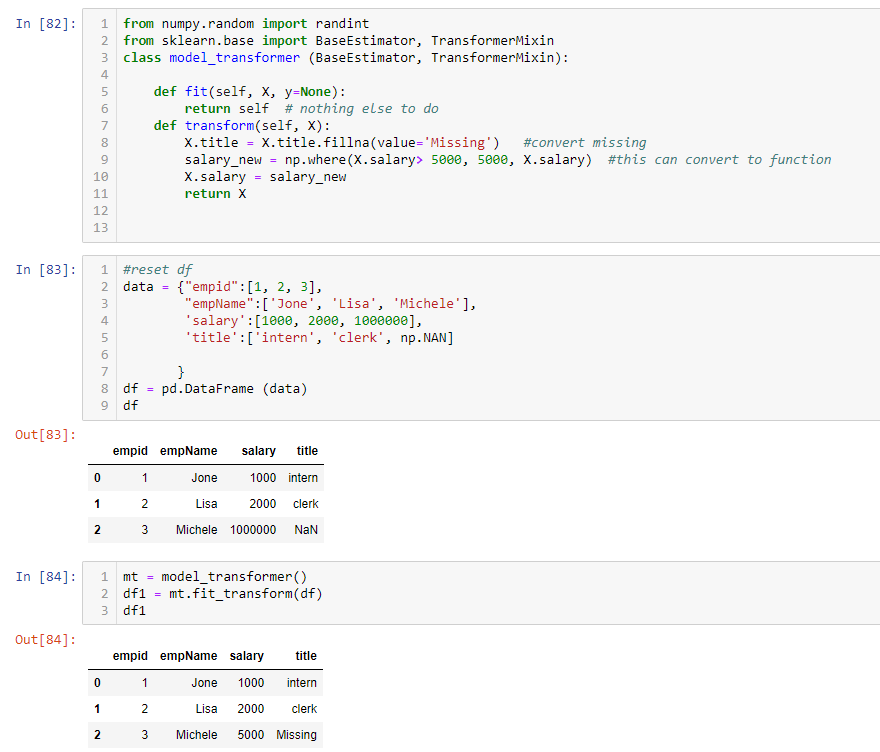
I put the code in the transform function and create a custom transform called model_transformer. Let us see if the custom transformer will work. I reset the data frame in cell 83. Now in cell 84, I first instantiate model_transformer class and give the name mt. Then I use the fit_transform function of the class to preprocess the data frame. The result shows 84, which is the same as 81. The class basically packages all functions together and transforms data in one step. That is neat.
Let us say, you have a new dataset for testing. Can this instance handle it?
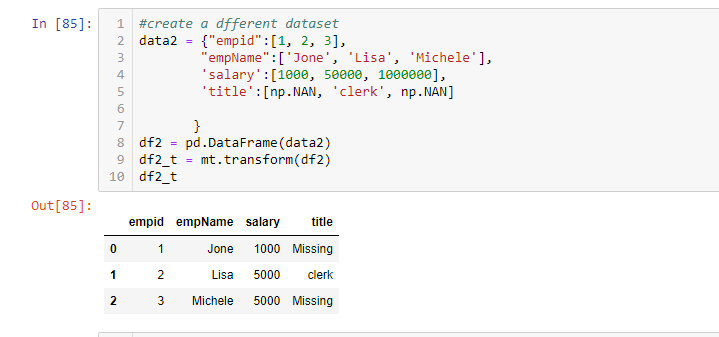
I created a new dataset, with values changed in row 4, 5. The mt instance gets the job done.
If I want to use the mt instance in another notebook and do transformation, will that work?
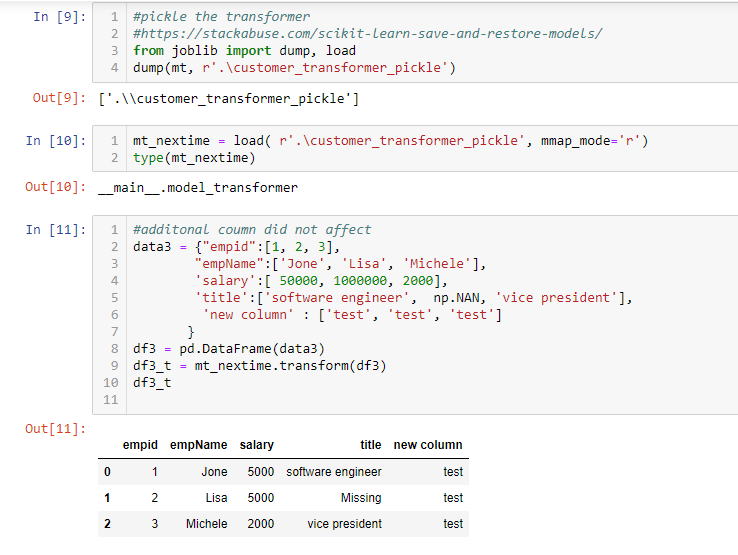
Here I can pickle the transformer and then reload it with a different name. In cell 11, I create a different dataset and the loaded instance process data just fine. (For simplicity, I did it in the same notebook, but you might need to include class definition when you use another notebook for it to work so that python knows where to find it)
Can the class remember the value of training? In the previous code, I simplified it with hard code to see how class and pickle work.
Here I have a training dataset and a testing dataset, both with different mean values for salary and bonus. We use mean as a simple example, but that applies to other scenarios such as capping outliers.
Let us see if I fit with the training data and then transform with the testing data, if the mean value from training can be used to fill the null value of testing.
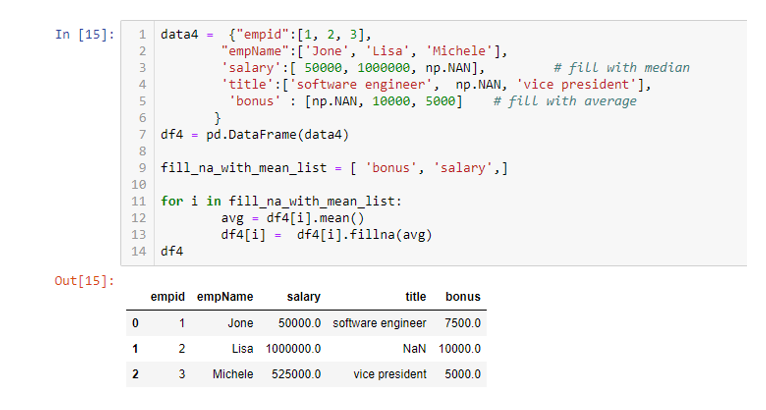
Hard coded python script converts salary and bonus null value with avg.
Create a transformer
![]()
This custom transformer is able to handle training data. But obviously, it has no memory. You can see when it transforms testing data, it fills the null value with testing data mean (yellow shade below).
![]()
In order to let the class remember the value, you will need to create an instance variable at line 8, where you can save the training value. The instance variable will be different when you fit different training instances. When you fit the model with training data, the average of each column was saved into the instance variable (line 20). When you transform with testing data, these values are retrieved by set_null_as_avg function see line 14 and 15.
![]()
Let us give a try
![]()
You can see df5 no longer uses the testing data average, but instead uses the training data average. In fact, you can check the instance variable value in cell 23. Once you fit the model with training data, these average values have been saved there.
I hope the smart class can save you some time from the tedious work.
As always, the Jupyter code file can be found here.
Thanks for reading
Wenlei