Change data capture (CDC) is very important for ETL developer. It is the foundation of data incremental loading. A lot of companies now require data to be refreshed on the daily basis. If full load of ETL process takes less than 24 hours, you can still manage to do it with full load daily. As source data is growing, the full load cannot be finished within 24 hours. Now, it is the time that CDC comes in to play.
In SAP data service, table comparison transform can be used to compare incoming data with existing data and further update the existing data. It has some configurations which might affect the outcome of CDC, I would like to use some dummy data to see different CDC behaviors so that we can understand the configuration and know when to use it.
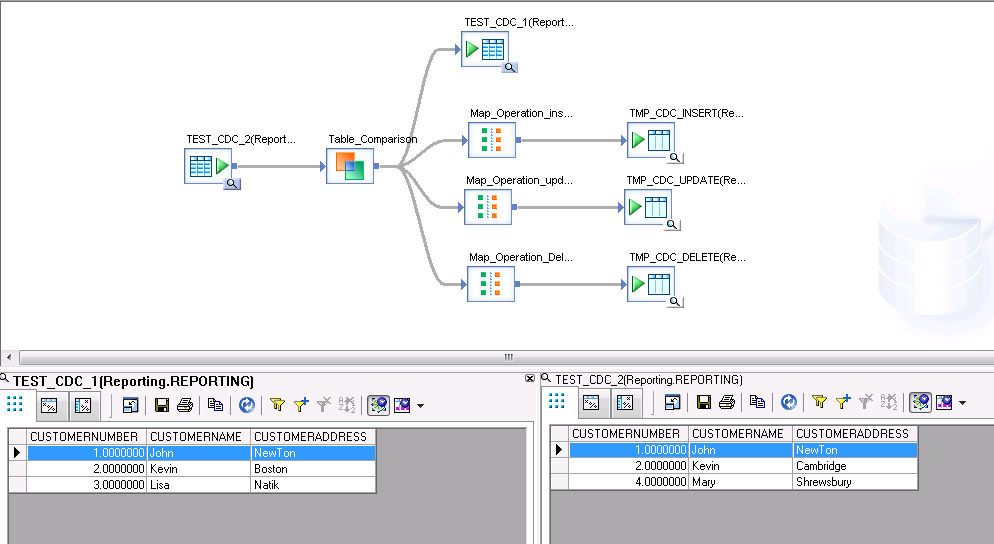
Let us first create a customer info dummy table test_cdc_1, we use it as an existing table
 In this case, I have 3 persons and they have the address info listed in table. Now we want to see CDC’s three actions, insert, update, and delete. We design an incoming table, test_cdc_2. So we can see these 3 actions.
In this case, I have 3 persons and they have the address info listed in table. Now we want to see CDC’s three actions, insert, update, and delete. We design an incoming table, test_cdc_2. So we can see these 3 actions.
 In this table, you can see John keeps the same location, Kevin changed location to Cambridge, Lisa is not customer anymore. But we have new customer Mary. So John keep the same, Kevin will need to be updated, Lisa will be deleted and Mary will be inserted.
I created data service job like the follows, what is displayed is data flow part.
In this table, you can see John keeps the same location, Kevin changed location to Cambridge, Lisa is not customer anymore. But we have new customer Mary. So John keep the same, Kevin will need to be updated, Lisa will be deleted and Mary will be inserted.
I created data service job like the follows, what is displayed is data flow part.